Acest ghid va ilustra cum să utilizați VectorStoreRetrieverMemory folosind cadrul LangChain.
Cum se utilizează VectorStoreRetrieverMemory în LangChain?
VectorStoreRetrieverMemory este biblioteca LangChain care poate fi folosită pentru a extrage informații/date din memorie folosind depozitele de vectori. Magazinele de vectori pot fi folosite pentru a stoca și gestiona date pentru a extrage eficient informațiile în funcție de solicitare sau interogare.
Pentru a afla procesul de utilizare a VectorStoreRetrieverMemory în LangChain, parcurgeți următorul ghid:
Pasul 1: Instalați module
Începeți procesul de utilizare a memoriei retriever instalând LangChain folosind comanda pip:
pip install langchain
Instalați modulele FAISS pentru a obține datele folosind căutarea de similaritate semantică:
pip install faiss-gpu 
Instalați modulul chromadb pentru utilizarea bazei de date Chroma. Funcționează ca magazin de vectori pentru a construi memoria pentru retriever:
pip install chromadb 
Este necesar să se instaleze un alt modul tiktoken, care poate fi utilizat pentru a crea jetoane prin conversia datelor în bucăți mai mici:
pip install tiktoken 
Instalați modulul OpenAI pentru a-și folosi bibliotecile pentru a construi LLM-uri sau chatbot-uri folosind mediul său:
pip install openai 
Configurați mediul pe Python IDE sau notebook folosind cheia API din contul OpenAI:
import tuimport getpass
tu . aproximativ [ „OPENAI_API_KEY” ] = getpass . getpass ( „Cheia API OpenAI:” )
Pasul 2: importați biblioteci
Următorul pas este să obțineți bibliotecile din aceste module pentru utilizarea memoriei retriever în LangChain:
din langchain. solicitări import PromptTemplatedin datetime import datetime
din langchain. llms import OpenAI
din langchain. înglobări . openai import OpenAIEmbeddings
din langchain. lanţuri import ConversationChain
din langchain. memorie import VectorStoreRetrieverMemory
Pasul 3: Inițializarea Vector Store
Acest ghid folosește baza de date Chroma după importarea bibliotecii FAISS pentru a extrage datele folosind comanda de intrare:
import faissdin langchain. docstore import ÎnMemoryDocstore
#importing biblioteci pentru configurarea bazelor de date sau a magazinelor de vectori
din langchain. vectorstores import FAISS
#creați încorporații și texte pentru a le stoca în magazinele de vectori
dimensiunea_incorporare = 1536
index = faiss. IndexFlatL2 ( dimensiunea_incorporare )
embedding_fn = OpenAIEmbeddings ( ) . interogare_încorporare
vectorstore = FAISS ( embedding_fn , index , ÎnMemoryDocstore ( { } ) , { } )
Pasul 4: Construirea unui Retriever susținut de un magazin de vectori
Construiește memoria pentru a stoca cele mai recente mesaje din conversație și a obține contextul chat-ului:
copoi = vectorstore. ca_retriever ( search_kwargs = dict ( k = 1 ) )memorie = VectorStoreRetrieverMemory ( copoi = copoi )
memorie. salvare_context ( { 'intrare' : 'Imi place sa mananc pizza' } , { 'ieșire' : 'fantastic' } )
memorie. salvare_context ( { 'intrare' : „Sunt bun la fotbal” } , { 'ieșire' : 'Bine' } )
memorie. salvare_context ( { 'intrare' : „Nu-mi place politica” } , { 'ieșire' : 'sigur' } )
Testați memoria modelului folosind intrarea furnizată de utilizator cu istoricul acestuia:
imprimare ( memorie. load_memory_variables ( { 'prompt' : 'Ce sport ar trebui sa ma uit?' } ) [ 'istorie' ] ) 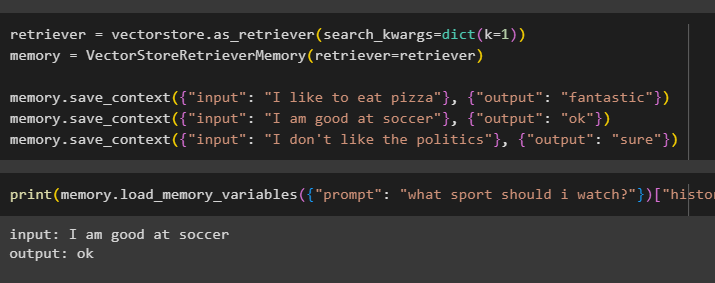
Pasul 5: Utilizarea Retriever într-un lanț
Următorul pas este utilizarea unui retriever de memorie cu lanțuri prin construirea LLM folosind metoda OpenAI() și configurarea șablonului prompt:
llm = OpenAI ( temperatura = 0 )_DEFAULT_TEMPLATE = ''' Este o interacțiune între un om și o mașină
Sistemul produce informații utile cu detalii folosind context
Dacă sistemul nu are răspunsul pentru tine, pur și simplu spune că nu am răspunsul
Informații importante din conversație:
{istorie}
(dacă textul nu este relevant, nu-l folosi)
Chat curent:
Om: {input}
AI:'''
PROMPT = PromptTemplate (
variabile_de intrare = [ 'istorie' , 'intrare' ] , șablon = _DEFAULT_TEMPLATE
)
#configurează ConversationChain() folosind valorile parametrilor săi
conversație_cu_rezumat = ConversationChain (
llm = llm ,
prompt = PROMPT ,
memorie = memorie ,
verboroasă = Adevărat
)
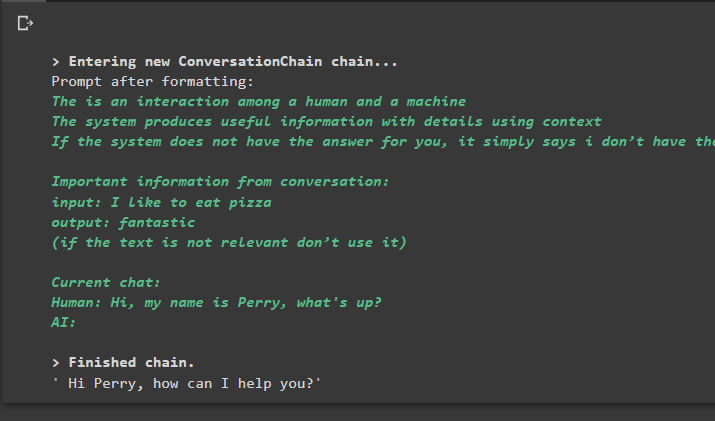
conversație_cu_rezumat. prezice ( intrare = 'Buna, ma numesc Perry, ce e?' )
Ieșire
Executarea comenzii rulează lanțul și afișează răspunsul oferit de model sau LLM:
Continuați conversația folosind promptul bazat pe datele stocate în magazinul de vectori:
conversație_cu_rezumat. prezice ( intrare = 'care este sportul meu preferat?' ) 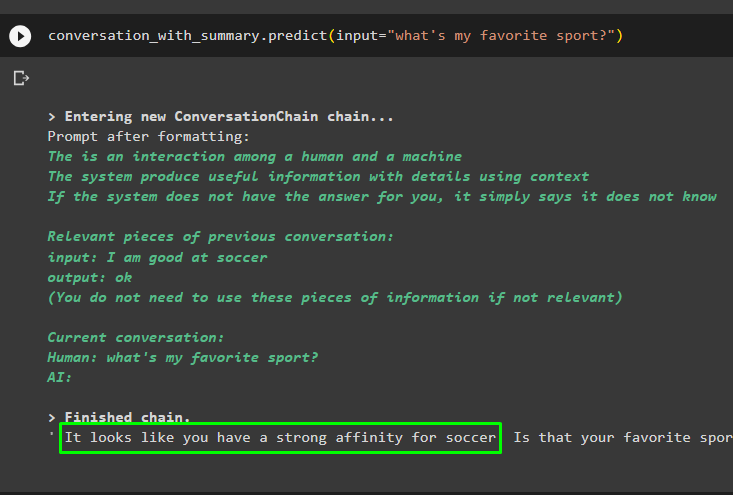
Mesajele anterioare sunt stocate în memoria modelului, care poate fi folosită de model pentru a înțelege contextul mesajului:
conversație_cu_rezumat. prezice ( intrare = „Care este mâncarea mea preferată” ) 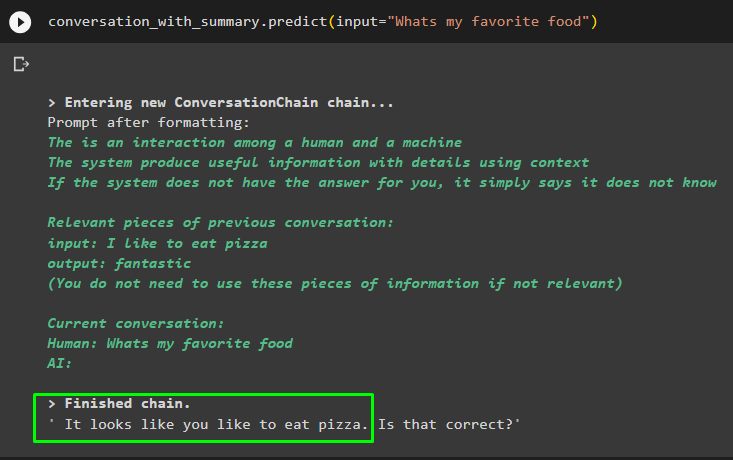
Obțineți răspunsul oferit modelului într-unul dintre mesajele anterioare pentru a verifica cum funcționează memoria retriever cu modelul de chat:
conversație_cu_rezumat. prezice ( intrare = 'Care este numele meu?' )Modelul a afișat corect rezultatul utilizând căutarea de similaritate din datele stocate în memorie:
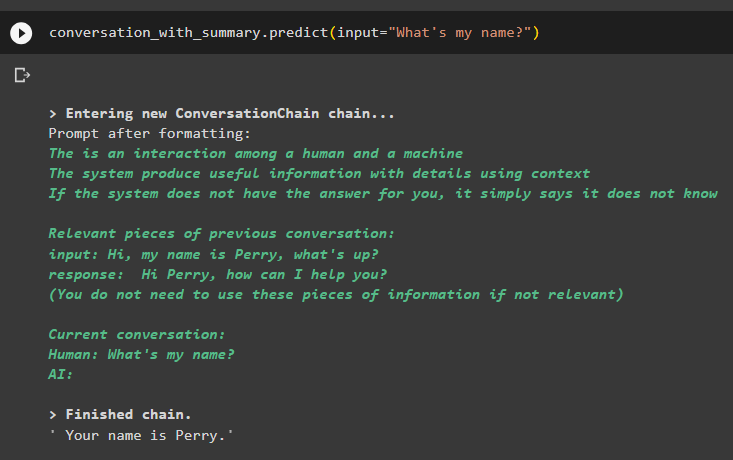
Acesta este totul despre utilizarea vectorului magazin retriever în LangChain.
Concluzie
Pentru a utiliza memorie retriever bazată pe un magazin de vectori în LangChain, pur și simplu instalați modulele și cadrele și configurați mediul. După aceea, importați bibliotecile din module pentru a construi baza de date folosind Chroma și apoi setați șablonul prompt. Testați retriever-ul după stocarea datelor în memorie inițiind conversația și punând întrebări legate de mesajele anterioare. Acest ghid a elaborat procesul de utilizare a bibliotecii VectorStoreRetrieverMemory în LangChain.