UTF-8 înseamnă „ Format de transformare Unicode pe 8 biți ” și corespunde unui format de codare excelent care asigură afișarea adecvată a caracterelor pe toate dispozitivele, indiferent de limba/scriptul utilizat. De asemenea, acest format este de asistență pentru paginile web și este utilizat pentru stocarea, procesarea și transmiterea datelor text pe internet.
Acest tutorial acoperă domeniile de conținut menționate mai jos:
- Ce este codificarea UTF-8?
- Cum funcționează codarea UTF-8?
- Cum sunt calculate valorile punctelor de cod?
- Cum se codifică/decodează UTF-8 în JavaScript?
- Codificare/Decodare UTF-8 în JavaScript Folosind metodele „encodeURIComponent()” și „decodeURIComponent()”.
- Codificare/Decodare UTF-8 în JavaScript Folosind metodele „encodeURI()” și „decodeURI()”.
- Codificare/Decodare UTF-8 în JavaScript folosind expresiile regulate.
- Concluzie
Ce este codificarea UTF-8?
„ Codificare UTF-8 ” este procedura de transformare a secvenței de caractere Unicode într-un șir codificat cuprinzând octeți de 8 biți. Această codificare poate reprezenta o gamă largă de caractere în comparație cu celelalte codificări de caractere.
Cum funcționează codarea UTF-8?
În timp ce reprezintă caractere în UTF-8, fiecare punct de cod individual este reprezentat de unul sau mai mulți octeți. Mai jos este defalcarea punctelor de cod din intervalul ASCII:
- Un singur octet reprezintă punctele de cod în intervalul ASCII (0-127).
- Doi octeți reprezintă punctele de cod în intervalul ASCII (128-2047).
- Trei octeți reprezintă punctele de cod în intervalul ASCII (2048-65535).
- Patru octeți reprezintă punctele de cod în intervalul ASCII (65536-1114111).
Este de așa natură încât primul octet al unui „ UTF-8 ” secvența este denumită ” octet lider ” care oferă informații despre numărul de octeți din secvență și valoarea punctului de cod a caracterului.
„Octetul lider” pentru o secvență de un singur, doi, trei și patru octeți este în intervalul (0-127), (194-233), (224-239) și, respectiv, (240-247).
Restul octeților în secvență se numesc „ trasând ” octeți. Octeții pentru o secvență de doi, trei și patru octeți sunt toți în intervalul (128-191). Este de așa natură încât valoarea punctului de cod a caracterului poate fi calculată prin analiza octeților de început și de final.
Cum sunt calculate valorile punctelor de cod?
Valorile punctelor de cod pentru diferite secvențe de octeți sunt calculate după cum urmează:
- Secvență de doi octeți: Punctul de cod este echivalent cu „((lb – 194) * 64) + (tb – 128)”.
- Secvență de trei octeți : Punctul de cod este echivalent cu „((lb – 224) * 4096) + ((tb1 – 128) * 64) + (tb2 – 128)”.
- Secvență de patru octeți : Punctul de cod este echivalent cu „((lb – 240) * 262144) + ((tb1 – 128) * 4096) + ((tb2 – 128) * 64) + (tb3 – 128)”.
Cum se codifică/decodează UTF-8 în JavaScript?
Codificarea și decodificarea UTF-8 în JavaScript pot fi efectuate prin abordările de mai jos:
- „ enodeURIComponent() ' și ' decodeURIComponent() ” Metode.
- „ encodeURI() ' și ' decodeURI() ” Metode.
- Expresii obisnuite.
Abordarea 1: Codificarea/Decodarea UTF-8 în JavaScript Folosind metodele „encodeURIComponent()” și „decodeURIComponent()”
„ encodeURIComponent() ” metoda codifică o componentă URI. De asemenea, poate codifica caractere speciale precum @, &, :, +, $, # etc. decodeURIComponent() ”, totuși, decodifică o componentă URI. Aceste metode pot fi utilizate pentru a codifica și, respectiv, a decoda valorile transmise la UTF-8.
Sintaxă(Metoda „encodeURIComponent()”)
encodeURIComponent ( X )În sintaxa dată, „ X ” indică URI-ul care trebuie codificat.
Valoare returnată
Această metodă a preluat un URI codificat ca șir.
Sintaxă(Metoda „decodeURIComponent()”)
decodeURIComponent ( X )Aici, ' X ” se referă la URI-ul de decodat.
Valoare returnată
Această metodă oferă URI-ul decodat.
Exemplul 1: codificarea UTF-8 în JavaScript
Acest exemplu codifică șirul transmis la o valoare UTF-8 codificată cu ajutorul unei funcții definite de utilizator:
întoarcere unescape ( encodeURIComponent ( X ) ) ;
}
lasa val = 'Aici' ;
consolă. Buturuga ( „Valoare dată -> „ + val ) ;
lasă encodeVal = encode_utf8 ( val ) ;
consolă. Buturuga ( „Valoare codificată -> „ + encodeVal ) ;
În aceste linii de cod, efectuați pașii de mai jos:
- În primul rând, definiți funcția „ encode_utf8() ” care codifică șirul transmis reprezentat de parametrul specificat.
- Această codificare se face de către „ encodeURIComponent() ” în definiția funcției.
- Notă: „ unscape() ” metoda înlocuiește orice secvență de escape cu caracterul reprezentat de aceasta.
- După aceea, inițializați valoarea de codat și afișați-o.
- Acum, invocați funcția definită și transmiteți combinația definită de caractere ca argumente pentru a codifica această valoare în UTF-8.
Ieșire
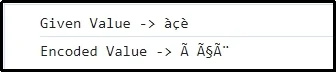
Aici, se poate presupune că caracterele individuale sunt reprezentate și codificate în UTF-8 în consecință.
Exemplul 2: Decodificarea UTF-8 în JavaScript
Demonstrația codului de mai jos decodifică valoarea transmisă (sub formă de caractere) la o reprezentare codificată UTF-8:
întoarcere decodeURIComponent ( evadare ( X ) ) ;
}
lasa val = 'çè' ;
consolă. Buturuga ( „Valoare dată -> „ + val ) ;
lasa sa decodeze = decode_utf8 ( val ) ;
consolă. Buturuga ( „Valoare decodificată -> „ + decodifica ) ;
În acest bloc de cod:
- De asemenea, definiți funcția „ decode_utf8() ” care decodifică combinația de caractere transmisă prin intermediul „ decodeURIComponent() ” metoda.
- Notă: „ evadare() ” metoda preia un șir nou în care diferite caractere sunt înlocuite cu secvențe de evadare hexazecimale.
- După aceea, specificați combinația de caractere de decodat și accesați funcția definită pentru a efectua decodarea în UTF-8 în mod corespunzător.
Ieșire

Aici, se poate sugera că valoarea codificată din exemplul anterior este decodificată la valoarea implicită.
Abordarea 2: Codificarea/Decodarea UTF-8 în JavaScript Folosind metodele „encodeURI()” și „decodeURI()”
„ encodeURI() ”codifică un URI prin înlocuirea fiecărei instanțe de mai multe caractere cu un număr de secvențe de evadare reprezentând codificarea UTF-8 a caracterului. În comparație cu „ encodeURIComponent() ”, această metodă specifică codifică caractere limitate.
„ decodeURI() ”, totuși, decodifică URI-ul (codat). Aceste metode pot fi implementate în combinație pentru a codifica și decoda combinația de caractere într-o valoare codificată UTF-8.
Sintaxă(Metoda encodeURI())
encodeURI ( X )În sintaxa de mai sus, „ X ” corespunde valorii care trebuie codificată ca URI.
Valoare returnată
Această metodă preia valoarea codificată sub forma unui șir.
Sintaxă(Metoda decodeURI())
decodeURI ( X )Aici, ' X ” reprezintă URI-ul codificat de decodat.
Valoare returnată
Returnează URI-ul decodat ca șir.
Exemplul 1: codificarea UTF-8 în JavaScript
Această demonstrație codifică combinația de caractere transmisă la o valoare UTF-8 codificată:
întoarcere unescape ( encodeURI ( X ) ) ;
}
lasa val = 'Aici' ;
consolă. Buturuga ( „Valoare dată -> „ + val ) ;
lasă encodeVal = encode_utf8 ( val ) ;
consolă. Buturuga ( „Valoare codificată -> „ + encodeVal ) ;
Aici, amintiți-vă abordările pentru definirea unei funcții alocate pentru codificare. Acum, aplicați metoda „encodeURI()” pentru a reprezenta combinația de caractere transmisă ca șir codificat UTF-8. După aceea, de asemenea, definiți caracterele care trebuie evaluate și invocați funcția definită trecând valoarea definită ca argumente pentru a efectua codificarea.
Ieșire
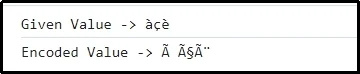
Aici, este evident că combinația de caractere transmisă este codificată cu succes.
Exemplul 2: Decodarea UTF-8 în JavaScript
Demonstrația codului de mai jos decodifică valoarea codificată UTF-8 (în exemplul anterior):
întoarcere decodeURI ( evadare ( X ) ) ;
}
lasa val = 'çè' ;
consolă. Buturuga ( „Valoare dată -> „ + val ) ;
lasa sa decodeze = decode_utf8 ( val ) ;
consolă. Buturuga ( „Valoare decodificată -> „ + decodifica ) ;
Conform acestui cod, declarați funcția „ decode_utf8() ” care cuprinde parametrul declarat care reprezintă combinația de caractere de decodat folosind „ decodeURI() ” metoda. Acum, specificați valoarea de decodat și invocați funcția definită pentru a aplica decodarea la „ UTF-8 ” reprezentare.
Ieșire
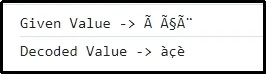
Acest rezultat implică faptul că valoarea codificată anterior este decisă în consecință.
Abordarea 3: Codificarea/Decodarea UTF-8 în JavaScript folosind expresiile regulate
Această abordare aplică codificarea astfel încât șirul unicode multi-octeți să fie codificat la mai multe caractere UTF-8 pe un singur octet. De asemenea, decodificarea este efectuată astfel încât șirul codificat să fie decodat înapoi la caractere Unicode pe mai mulți octeți.
Exemplul 1: codificarea UTF-8 în JavaScript
Codul de mai jos codifică șirul unicode multi-octeți în caractere UTF-8 pe un singur octet:
dacă ( tip de val != 'şir' ) arunca nou Eroare de scris ( „Parametrul” val „nu este un șir” ) ;
const string_utf8 = val. a inlocui (
/[\u0080-\u07ff]/g , // U+0080 - U+07FF => 2 octeți 110yyyyy, 10zzzzzz
funcţie ( X ) {
a fost afară = X. charCodeAt ( 0 ) ;
întoarcere Şir . de laCharCode ( 0xc0 | afară >> 6 , 0x80 | afară & 0x3f ) ; }
) . a inlocui (
/[\u0800-\uffff]/g , // U+0800 - U+FFFF => 3 octeți 1110xxxx, 10yyyyyy, 10zzzzzz
funcţie ( X ) {
a fost afară = X. charCodeAt ( 0 ) ;
întoarcere Şir . de laCharCode ( 0xe0 | afară >> 12 , 0x80 | afară >> 6 & 0x3F , 0x80 | afară & 0x3f ) ; }
) ;
consolă. Buturuga ( 'Valoare codificată folosind expresia regulată -> ' + string_utf8 ) ;
}
encodeUTF8 ( 'Aici' )
În acest fragment de cod:
- Definiți funcția „ encodeUTF8() ” cuprinzând parametrul care reprezintă valoarea care trebuie codificată ca “ UTF-8 ”.
- În definiția sa, aplicați o verificare asupra valorii transmise care nu este șirul folosind „ tip de ” operator și returnați excepția personalizată specificată prin intermediul „ arunca ” cuvânt cheie.
- După aceea, aplicați „ charCodeAt() ' și ' fromCharCode() ” metode de a prelua Unicode-ul primului caracter din șir și de a transforma valoarea Unicode dată în caractere, respectiv.
- În cele din urmă, invocați funcția definită pasând secvența dată de caractere pentru a codifica această valoare ca „ UTF-8 ” reprezentare.
Ieșire

Această ieșire înseamnă că codificarea este efectuată în mod corespunzător.
Exemplul 2: Decodificarea UTF-8 în JavaScript
În această demonstrație, secvența de caractere este decodificată în „ UTF-8 ” reprezentare:
dacă ( tip de val != 'şir' ) arunca nou Eroare de scris ( „Parametrul” val „nu este un șir” ) ;
const str = val. a inlocui (
/[\u00e0-\u00ef][\u0080-\u00bf][\u0080-\u00bf]/g ,
funcţie ( X ) {
a fost afară = ( ( X. charCodeAt ( 0 ) & 0x0f ) << 12 ) | ( ( X. charCodeAt ( 1 ) & 0x3f ) << 6 ) | ( X. charCodeAt ( 2 ) & 0x3f ) ;
întoarcere Şir . de laCharCode ( afară ) ; }
) . a inlocui (
/[\u00c0-\u00df][\u0080-\u00bf]/g ,
funcţie ( X ) {
a fost afară = ( X. charCodeAt ( 0 ) & 0x1f ) < '+str);
}
decodeUTF8('à çè')
În acest cod:
- În mod similar, definiți funcția „ decodeUTF8() ” având parametrul care se referă la valoarea transmisă de decodat.
- În definiția funcției, verificați starea șirului valorii transmise prin intermediul „ tip de ” operator.
- Acum, aplicați „ charCodeAt() ” pentru a prelua Unicode-ul primului, al doilea și, respectiv, al treilea șir de caractere.
- De asemenea, aplicați „ String.fromCharCode() ” pentru a transforma valorile Unicode în caractere.
- De asemenea, repetați această procedură din nou pentru a prelua Unicode-ul primului și celui de-al doilea șir de caractere și a transforma aceste valori Unicode în caractere.
- În cele din urmă, accesați funcția definită pentru a returna valoarea decodificată UTF-8.
Ieșire

Aici se poate verifica dacă decodarea este făcută corect.
Concluzie
Codificarea/decodificarea în reprezentarea UTF-8 poate fi efectuată prin intermediul „ enodeURIComponent()” și ' decodeURIComponent() metode, „ encodeURI() ' și ' decodeURI() ” sau folosind expresiile regulate.