Să ne uităm acum la utilitarul iconv al Linux din consola terminalului său. Deci, am executat instrucțiunea „iconv” cu indicatorul „-l” pentru a afișa toate seturile de caractere codificate cunoscute și cele mai utilizate pe ecranul terminalului nostru. Acesta va afișa seturile de caractere codificate împreună cu aliasurile acestora. Puteți vedea o listă lungă de seturi de caractere codificate după ce derulați puțin în jos.
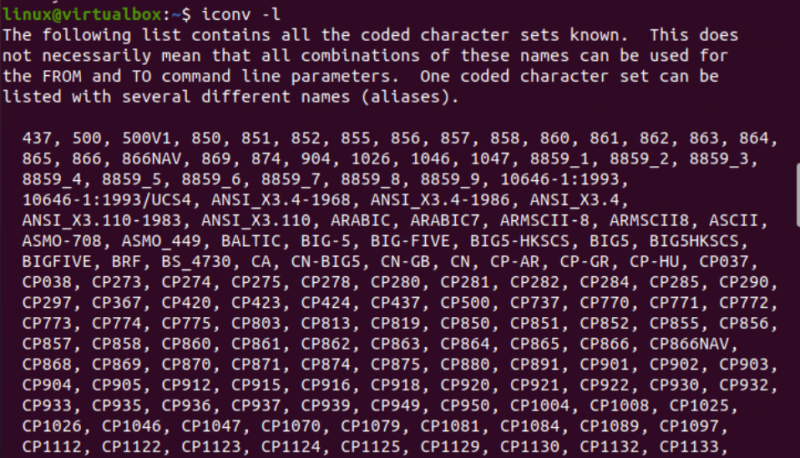
Acum, este timpul să începem cu implementarea comenzii iconv în Linux. În primul rând, avem nevoie de diferite tipuri de fișiere în sistemul nostru pentru a converti un tip de fișier în alt tip. Astfel, utilizăm interogarea „atingere” la terminalul consolei pentru a crea trei fișiere diferite, adică tipul Java, tipul C și tipul textului. Listând conținutul curent al directorului, veți găsi fișierele nou generate în acesta.
După aceasta, ne vom uita la tipul fiecărui fișier separat folosind interogarea „fișier” împreună cu numele fiecărui fișier. Această interogare are nevoie de opțiunea „-I” pentru a afișa tipul de set de caractere de codare pentru fiecare fișier separat. Dacă ați uitat să utilizați opțiunea „-I”, folosiți în schimb indicatorul „—mime”. Ambele steaguri „-I” și „—mime” funcționează la fel.
Acum, după ce am executat instrucțiunea „fișier” pentru fișierul de tip „txt”, am obținut codificarea tipului de caractere „US-ASCII”. În timp ce utilizați aceeași instrucțiune pentru fișierele Java și C, arată că ambele fișiere conțin codificare de tip de caractere „BINAR”. Împreună cu asta, această instrucțiune arată că toate aceste trei fișiere sunt goale.
Acum, vom ilustra utilizarea instrucțiunii iconv la consolă pentru a converti un anumit fișier de codificare a unui set de caractere într-o altă codare a unui set de caractere. Înainte de asta, trebuie să adăugăm niște coduri sau date în fișierele noastre. Prin urmare, am adăugat codul Java în fișierul „text.java”, codul C în fișierul „text.c” și am adăugat date text în fișierul „test.txt”. Interogarea cat a fost folosită aici pentru a afișa conținutul tuturor celor trei fișiere, așa cum este prezentat mai jos:
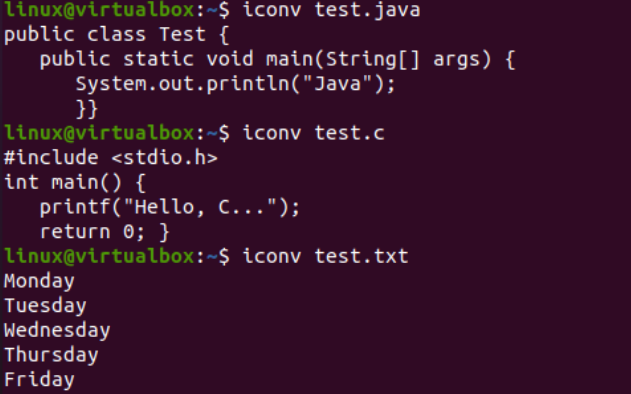
Acum că am adăugat datele cu succes, vom vedea din nou codificarea setului de caractere a acestor fișiere. Deci, am încercat aceeași instrucțiune de fișier în interiorul shell-ului cu indicatorul „-I” și numele fișierelor, adică test.txt, test.java și test.c. Rularea acestor trei instrucțiuni separat pentru toate cele trei fișiere arată că codarea setului de caractere a fost actualizată pentru fișierele Java și C, rămânând în același timp aceeași pentru fișierul text, adică US-ASCII. Codificarea fișierelor Java și C era anterior „binară”; acum, este „US-ASCII”. De asemenea, arată că fișierul text conține date text simplu, în timp ce celelalte două fișiere de cod conțin scripturile ca conținut.

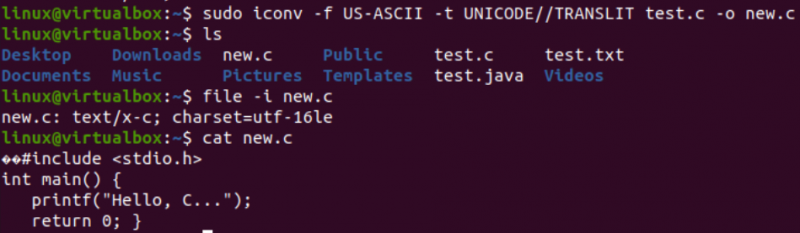
Este timpul să efectuați sarcina reală necesară pentru acest articol, adică să convertiți o codificare în alta folosind comanda iconv din shell. Astfel, am folosit instrucțiunea „iconv” din terminalul shell cu privilegiile „sudo”. Această comandă ia opțiunea „-f” înseamnă „de la”, iar opțiunea „-t” înseamnă „către”, adică de la o codificare la alta.
După opțiunea „-f”, trebuie să specificați codificarea pe care o are deja fișierul dvs., adică US-ASCII. În timp ce după opțiunea „-t”, trebuie să specificați codarea pe care doriți să o înlocuiți cu codificarea veche, adică UNICODE. Trebuie să specificați numele unui fișier folosit ca sursă cu opțiunea –o pentru a crea imaginea obiectului acestuia. Imaginea obiectului ar fi un alt fișier, adică „new.c”, de același tip, dar cu noua codificare și aceleași date.
După executarea următoarei instrucțiuni, veți obține un fișier nou în același director, adică, conform interogării „ls”. Acum, vom verifica codarea setului de caractere a unui fișier nou generat folosind instrucțiunea iconv. Vom folosi din nou instrucțiunea „fișier” cu opțiunea „-I” și noul nume de fișier, adică new.c.
Veți vedea că setul de caractere pentru acest fișier nou a fost diferit de setul de caractere al unui fișier vechi, adică setul de caractere UTF-16LE. Acest lucru se datorează faptului că am tradus codarea US-ASCII în codificarea UNICODE utilizând instrucțiunea iconv pentru fișierul nostru new.c. Interogarea „pisica” a afișat același cod C în fișier, dar a început cu unele caractere Unicode, așa cum a fost deja prezentat.
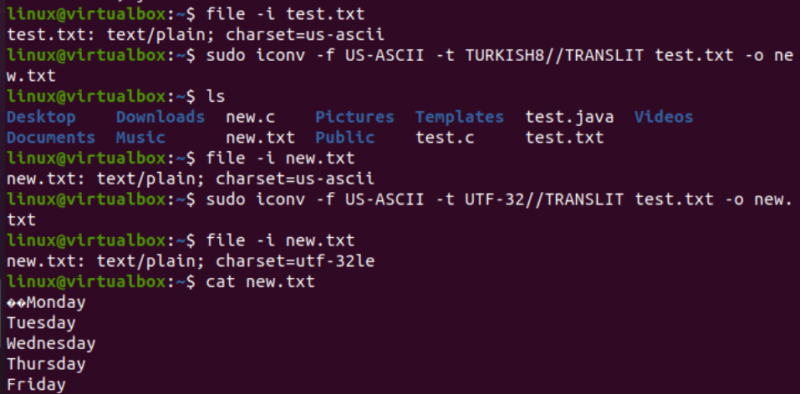
Într-un mod foarte similar, vom schimba codificarea fișierului text test.txt. Instrucțiunea de fișier arată că are o codificare US-ASCII pentru set de caractere. Comanda iconv a fost folosită cu același format pentru a converti codarea fișierului test.txt din US-ASCII în TURKISH8. Veți vedea că nu schimbă US-ASCII în turc.
După aceasta, am folosit aceeași comandă pentru a acoperi codificarea setului de caractere US-ASCII la UTF-32 pentru același fișier. De data asta, funcționează. Acest lucru se datorează faptului că uneori ar putea apărea o problemă la conversia unui set de codificare în altul, sau cealaltă codificare ar putea să nu o accepte.
Concluzie
Acest articol a discutat cum să utilizați instrucțiunile iconv Linux pentru a converti un set de caractere de codificare în altul folosind alias-urile. În acest fel, a trebuit să creăm câteva fișiere de diferite tipuri.