Cum să utilizați declarația de caz Pandas?
Declarațiile de caz pot fi create în mai multe moduri. Funcția NumPy where(), care folosește următoarea sintaxă fundamentală, este cea mai simplă modalitate de a construi o instrucțiune case într-un Pandas DataFrame:
df [ „numele coloanei” ] = np.unde ( condiție 1 , „valoare1”,np.unde ( condiție Două , „valoare2”,
np.unde ( condiție 3 , „valoare3”, „valoare4” ) ) )
Declarația de mai sus va verifica fiecare condiție pentru valoare și, dacă condiția este îndeplinită, va genera rezultatul sau va returna valoarea față de condiție.
Exemplul # 1: Declarație de caz Pandas Folosind funcția where().
Să creăm mai întâi un cadru de date, astfel încât să putem folosi declarația noastră case. Pentru a crea cadrul de date, vom importa mai întâi modulele numpy și panda, astfel încât să le putem folosi funcționalitățile. pd.Dataframe() va fi folosit pentru a crea cadrul nostru de date.

Am creat cadrul de date „df”. Un dicționar Python este transmis în interiorul pd.DataFrame() funcționează ca un argument cu chei și valori. Vom folosi funcția print() pentru a vedea cadrul de date.
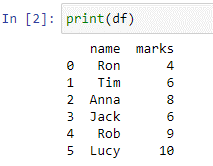
În cadrul de date „df” avem două coloane „nume” și „marcaj” cu valori [„Ron”, „Tim”, „Anna”, „Jack”, „Rob”, „Lucy”] și [4, 6 , 8, 6, 9, 10] respectiv. Să presupunem că acel nume este coloanele care stochează numele studenților și coloana „note” stochează scorul unui test recent. Acum, vom scrie o declarație case care adaugă o nouă coloană numită „remarci” ale cărei valori se bazează pe valorile specificate de noi, pentru fiecare condiție.

Metoda „numpy.where()” furnizează indicii de elemente dintr-o matrice, coloană sau listă de intrare care îndeplinesc condiția specificată. În cazul de comutare de mai sus, funcția np.where() verifică fiecare element din coloanele „marcaj”. Dacă valoarea este egală sau mai mică de 5, va returna „eșuare” ca ieșire. Dacă valoarea este mai mică sau egală cu 7, va reveni satisfăcător, iar dacă valoarea este mai mică sau egală cu 9, va returna „super.” Dacă nu există, rezultatul va fi excelent.
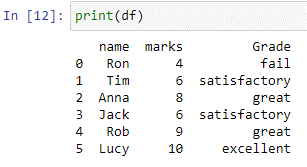
După cum se poate observa, noua coloană „observații” este creată în cadrul nostru de date „df”, stocând valorile returnate de declarația case de mai sus.
Exemplul # 2:
Să încercăm din nou declarația case de mai sus cu un cadru de date diferit. Să presupunem că trebuie să notăm jucătorii în funcție de obiectivele lor totale în turneul de fotbal anterior. Deci, să creăm un cadru de date pentru a stoca înregistrările jucătorilor de fotbal.
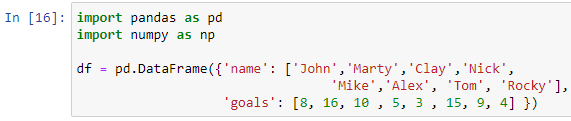
Am trecut un dicționar cu cheile „nume” și „obiective” în interiorul funcției pd.DataFrame() pentru a crea cadrul de date. Pentru a imprima cadrul nostru de date, vom folosi funcția de imprimare.
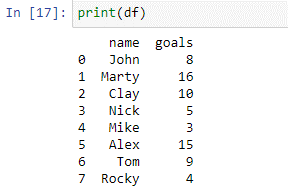
După cum se poate vedea în cadrul de date de mai sus, avem două coloane: „nume” și „obiective”. În numele coloanei, avem numele jucătorilor [‘John’, ‘Marty’, ‘Clay’, ‘Nick’, ‘Mike’, ‘Alex’, ‘Tom’, ‘Rocky’]. În „coloana” goluri, avem numărul total de goluri marcate de fiecare jucător în turneul anterior. Vom folosi acum declarația noastră de caz pentru a nota acești jucători în funcție de golurile pe care le-au marcat.

Cazul de mai sus este creat folosind funcția where(). În interiorul carcasei, funcția de instrucțiune verifică fiecare element din coloanele „marcaj” în raport cu condițiile. Dacă valoarea din coloana „obiective” este egală sau mai mică de 5, va returna „C”. Dacă valoarea din coloana „obiective” este egală sau mai mică de 9, va returna „B”. Va returna un „A” dacă valoarea din coloana „obiective” este egală sau mai mare de 10. Valorile returnate de declarație vor fi stocate în noua coloană „evaluare”. Să tipărim „df” pentru a vedea rezultatele.
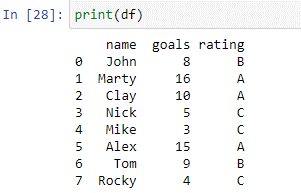
Noua coloană „evaluare” este creată cu succes folosind scriptul de mai sus.
Exemplul # 3: Declarația Pandas if-else Folosind funcția apply().
Axa rândului sau coloanei cadrului de date este utilizată de metoda apply() pentru a implementa o funcție. Ne putem crea propria noastră funcție definită și o putem folosi în cadrul nostru de date în panda. Acesta va cuprinde condiții dacă-altfel. Să ne creăm mai întâi cadrul de date, apoi vom crea o funcție în care vom folosi o instrucțiune if-else pentru a genera rezultatul. Pentru a crea cadrul de date, vom importa mai întâi modulul panda, apoi vom trece un dicționar în cadrul metodei pd.DataFrame().
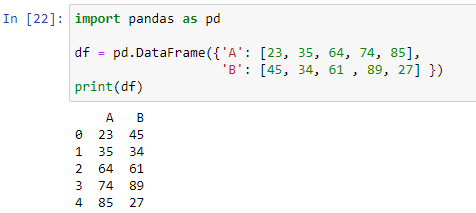
După cum se poate vedea, cadrul nostru de date este format din două coloane „A” care stochează valori numerice [23, 35, 64, 74, 85] și „B” cu valori [45, 34, 61, 89, 27]. Acum vom crea o funcție care va determina care valoare este mai mare între ambele coloane din fiecare rând al cadrului nostru de date.
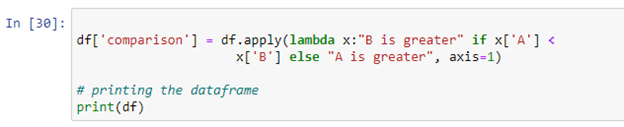
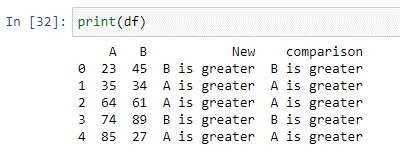
Puteți utiliza funcția lambda Python „pandas. DataFrame.apply()” pentru a rula o expresie. În Python, o funcție lambda este o funcție anonimă compactă care acceptă orice număr de argumente și execută o expresie. În scriptul de mai sus, am creat o declarație de condiție care va compara valoarea ambelor coloane și va stoca rezultatul în noua coloană „comparație”. Dacă valoarea coloanei „A” este mai mică decât valoarea coloanei „B”, va returna „B este mai mare”. Dacă condiția nu este îndeplinită, va returna „A este mai mare”.
Exemplul #4:
Să încercăm un alt exemplu folosind instrucțiunea if-else din cadrul funcției apply() cu un alt cadru de date.
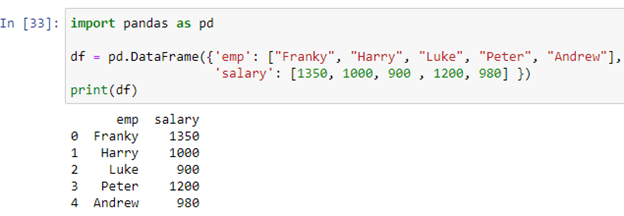
Să presupunem că cadrul nostru de date stochează înregistrările angajaților unei companii. Coloana „emp” stochează numele angajaților [„Franky”, „Harry”, „Luke”, „Peter”, „Andrew”], în timp ce coloana „salariu” stochează salariile fiecărui angajat [1350, 1000, 900 , 1200, 980] în cadrul de date „df”. Acum vom crea declarația noastră if-else folosind metoda apply().

Condiția de mai sus va verifica fiecare valoare din coloana „salariu” și va adăuga 200 la salariile angajaților unde valoarea salariului este mai mică sau egală cu 1000. Am stocat valorile returnate de la funcția apply() în noua coloană „ creştere'. Să vedem rezultatele din scriptul de mai sus.
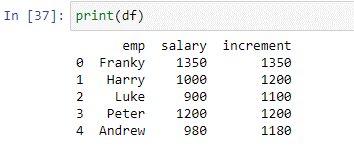
După cum puteți vedea, funcția a adăugat cu succes 200 la valorile care au fost mai mici sau egale cu 100. Valorile care au fost mai mari de 1000 au rămas neschimbate.
Concluzie:
În acest tutorial, am văzut că atunci când condiția este îndeplinită, o instrucțiune de acest tip, numită instrucțiune case, returnează o valoare. Am văzut cum puteți crea o declarație de caz pentru a efectua o operație sau o sarcină necesară. În acest tutorial, am folosit funcția np.where() și funcția apply() pentru a crea instrucțiuni case. Am implementat câteva exemple pentru a vă învăța cum să utilizați instrucțiunile case panda folosind funcția where() și cum să utilizați funcția apply() pentru a crea instrucțiuni case.