Acest ghid va explica listele crawlerelor din AWS.
Ce sunt List-Crawlerele în AWS?
Un crawler este o componentă a AWS Glue care este folosită pentru a accesa cu crawlere locația datelor și deduce acele informații înapoi în catalog. Informațiile pe care le colectează un crawler pot fi tipuri de date ale datelor, structura schemei sau, cu alte cuvinte, colectează metadate. Crawlerul poate fi folosit și cu catalogul de date, care este utilizat atunci când datele sunt mutate în ecosistemul Glue în timp ce se utilizează joburi ETL etc.
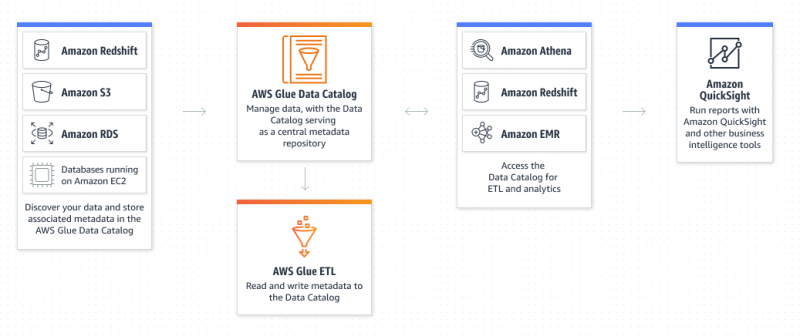
Ce este Amazon Glue Service?
AWS Glue este un serviciu Amazon Extract Transform and Load care permite utilizatorului să organizeze, să localizeze, să mute și să transforme toate datele. AWS Glue este fără server, deoarece utilizatorul nu are nevoie să furnizeze și să configureze serverele sau să gestioneze ciclurile de viață. Catalogul de date și crawlerele sunt componentele AWS Glue care acționează ca depozit de metadate persistente:

Cum se creează un crawler pe AWS?
Pentru a crea un crawler pe AWS, vizitați serviciul AWS Glue din AWS Management Console:
Mergeți în „ Crawlers ” făcând clic pe numele acesteia din panoul din stânga:
Faceți clic pe „ Creați un crawler butonul ”:
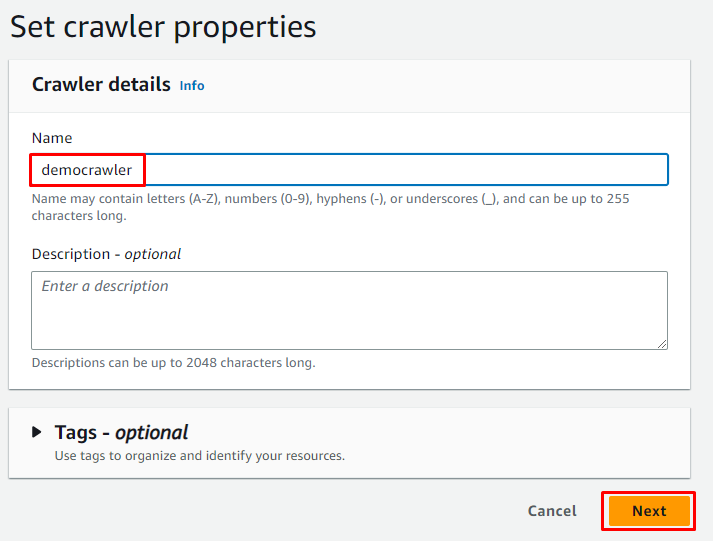
Tastați numele crawler-ului și faceți clic pe „ Următorul butonul ”:
Selectați opțiunea de mapare pentru tabelele lipite și faceți clic pe „ Adăugați o sursă butonul ” pentru a obține date de la:

Selectați serviciul S3 și faceți clic pe „ Răsfoiți S3 ” pentru a obține locația sursei:

Pur și simplu selectați folderul S3 și faceți clic pe „ Alege butonul ”:

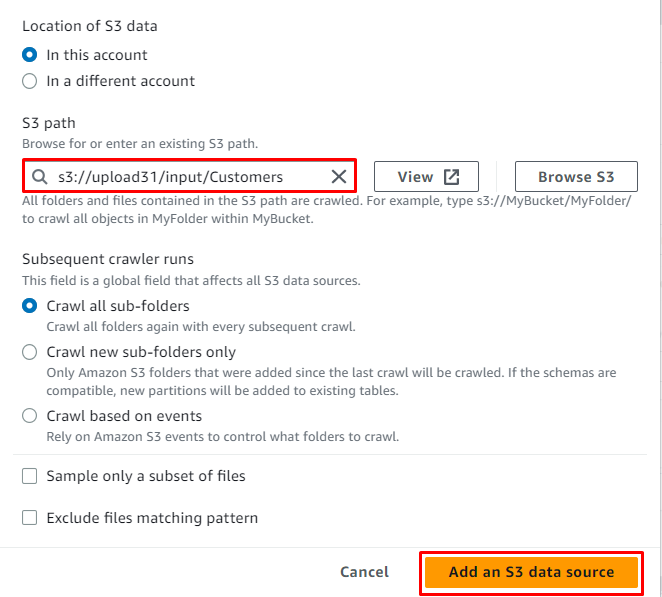
Odată ce locația este adăugată la sursă, faceți clic pe butonul „ Adăugați o sursă de date S3 butonul ”:
Faceți clic pe „ Următorul butonul ”:

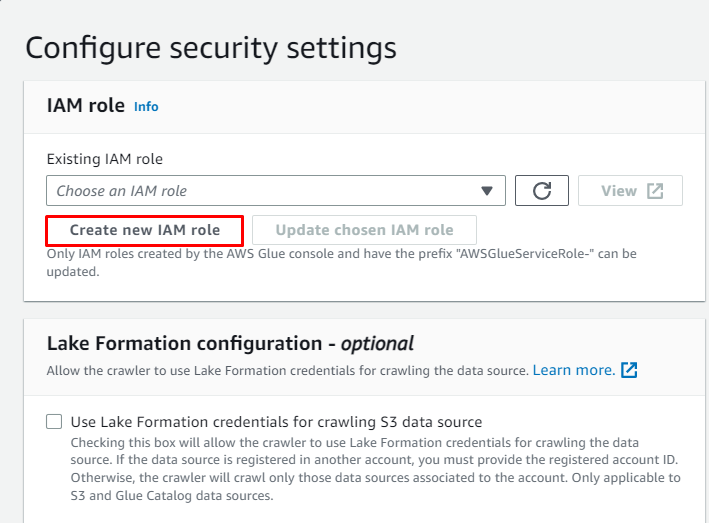
Faceți clic pe „ Creați un nou rol IAM butonul ” din “ Configurați setările de securitate ' secțiune:
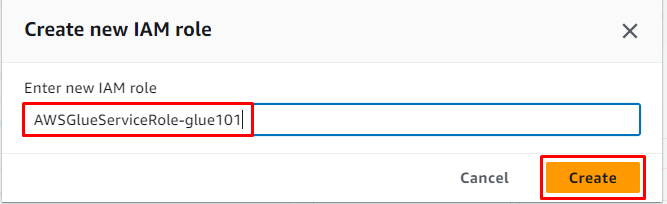
Introduceți numele rolului și faceți clic pe „ Crea butonul ”:
După aceea, pur și simplu faceți clic pe „ Următorul butonul ”:

Selectați baza de date țintă și introduceți numele care va fi folosit pentru tabel:
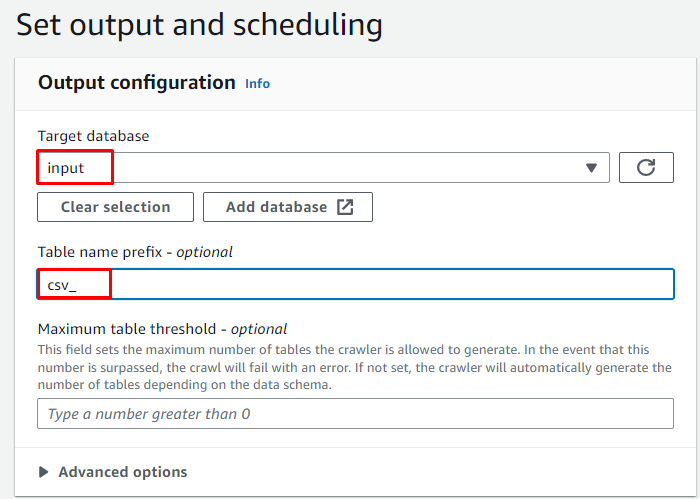
Programați crawler-ul pentru „ La cerere ” și faceți clic pe „ Următorul butonul ”:
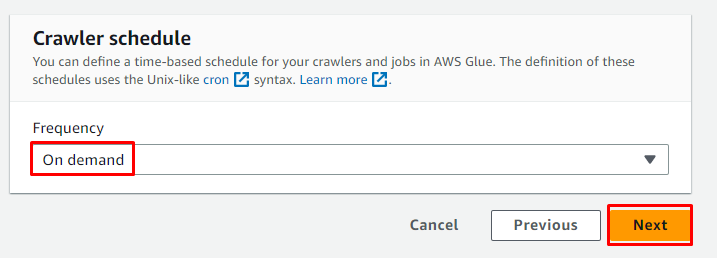
Examinați configurația și faceți clic pe „ Creați un crawler butonul ”:
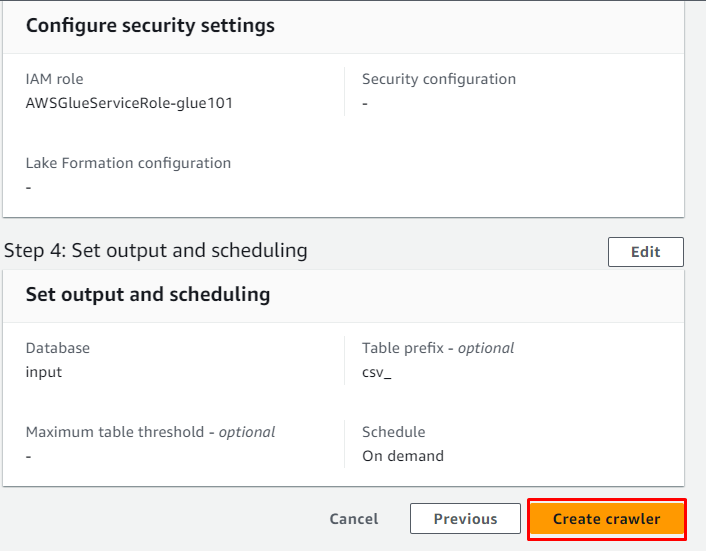
Crawler-ul a fost creat cu succes și poate fi folosit pentru a prelua datele de la sursă făcând clic pe „ Alerga butonul ”:

Acesta este totul despre crawlerele de listă din AWS.
Concluzie
ListCrawler este componenta serviciului AWS Glue care poate fi folosită pentru a accesa cu crawlere informații din surse și a reveni la catalog. Cataloagele de date și crawlerele pot fi utilizate pentru a colecta date pentru a obține informații despre date cunoscute sub denumirea de metadate. De asemenea, utilizatorul poate crea un crawler din AWS Glue pentru a obține date din serviciul S3 sau din alte surse și pentru a plasa tabele de creare în baza de date. Acest ghid a explicat ListCrawlerele din AWS și cum să le creați.