Schiță rapidă
Această postare va demonstra:
Cum să implementați ReAct Logic cu Document Store în LangChain
- Instalarea cadrelor
- Furnizarea cheii API OpenAI
- Import de biblioteci
- Folosind Wikipedia Explorer
- Testarea modelului
Cum se implementează ReAct Logic cu Document Store în LangChain?
Modelele lingvistice sunt antrenate pe un bazin imens de date scrise în limbi naturale precum engleza etc. Datele sunt gestionate și stocate în depozitele de documente, iar utilizatorul poate pur și simplu să încarce datele din magazin și să antreneze modelul. Antrenamentul modelului poate dura mai multe iterații, deoarece fiecare iterație face modelul mai eficient și îmbunătățit.
Pentru a afla procesul de implementare a logicii ReAct pentru lucrul cu depozitul de documente din LangChain, pur și simplu urmați acest ghid simplu:
Pasul 1: Instalarea cadrelor
În primul rând, începeți cu procesul de implementare a logicii ReAct pentru lucrul cu depozitul de documente prin instalarea cadrului LangChain. Instalarea cadrului LangChain va obține toate dependențele necesare pentru a obține sau importa bibliotecile pentru finalizarea procesului:
pip install langchain
Instalați dependențele Wikipedia pentru acest ghid, deoarece poate fi folosit pentru ca depozitele de documente să funcționeze cu logica ReAct:
pip install wikipedia 
Instalați modulele OpenAI folosind comanda pip pentru a obține bibliotecile și pentru a construi modele de limbaj mari sau LLM-uri:
pip install openai 
Pasul 2: Furnizarea cheii API OpenAI
După instalarea tuturor modulelor necesare, pur și simplu configura mediul folosind cheia API din contul OpenAI folosind următorul cod:
import tuimport getpass
tu . aproximativ [ „OPENAI_API_KEY” ] = getpass . getpass ( „Cheie API OpenAI:” )
Pasul 3: Importarea bibliotecilor
Odată configurat mediul, importați bibliotecile din LangChain care sunt necesare pentru a configura logica ReAct pentru lucrul cu depozitele de documente. Folosind agenți LangChain pentru a obține DocstoreExplaorer și agenți cu tipurile acestuia pentru a configura modelul de limbă:
din langchain. llms import OpenAIdin langchain. docstore import Wikipedia
din langchain. agenţi import initialize_agent , Instrument
din langchain. agenţi import AgentType
din langchain. agenţi . reacţiona . baza import DocstoreExplorer
Pasul 4: Utilizarea Wikipedia Explorer
Configurați „ docstore ” cu metoda DocstoreExplorer() și apelați metoda Wikipedia() în argumentul său. Construiți modelul de limbă mare folosind metoda OpenAI cu „ text-davinci-002 ” model după setarea instrumentelor pentru agent:
docstore = DocstoreExplorer ( Wikipedia ( ) )unelte = [
Instrument (
Nume = 'Căutare' ,
func = docstore. căutare ,
Descriere = „Este folosit pentru a adresa interogări/indemnări cu căutarea” ,
) ,
Instrument (
Nume = 'Priveşte în sus' ,
func = docstore. priveşte în sus ,
Descriere = „Este folosit pentru a adresa interogări/indemnări cu căutare” ,
) ,
]
llm = OpenAI ( temperatura = 0 , numele modelului = „text-davinci-002” )
#definirea variabilei prin configurarea modelului cu agentul
reacţiona = initialize_agent ( unelte , llm , agent = AgentType. REACT_DOCSTORE , verboroasă = Adevărat )
Pasul 5: Testarea modelului
Odată ce modelul este construit și configurat, setați șirul de întrebări și rulați metoda cu variabila întrebare în argumentul său:
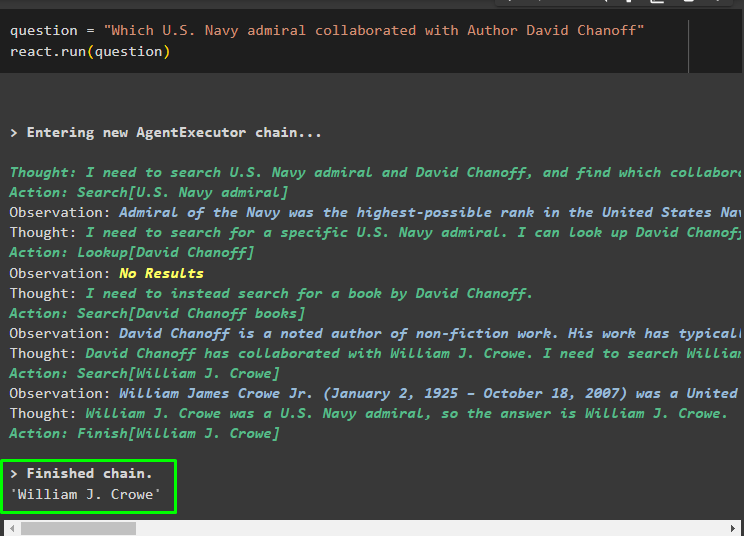
întrebare = „Care amiral al Marinei SUA a colaborat cu autorul David Chanoff”reacţiona. alerga ( întrebare )
Odată ce variabila întrebare este executată, modelul a înțeles întrebarea fără nici un șablon de prompt extern sau antrenament. Modelul este antrenat automat folosind modelul încărcat la pasul anterior și generând text corespunzător. Logica ReAct lucrează cu depozitele de documente pentru a extrage informații pe baza întrebării:
Pune o altă întrebare din datele furnizate modelului din magazinele de documente și modelul va extrage răspunsul din magazin:
întrebare = „Autorul David Chanoff a colaborat cu William J Crowe, care a servit sub ce președinte?”reacţiona. alerga ( întrebare )
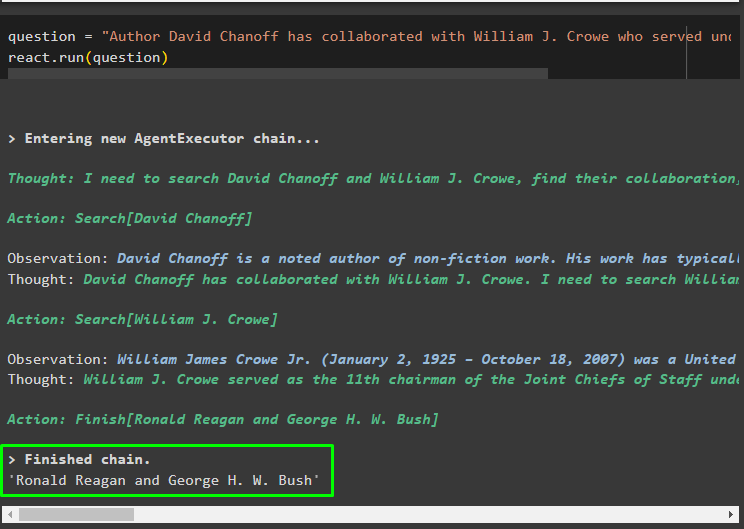
Acesta este totul despre implementarea logicii ReAct pentru lucrul cu depozitul de documente în LangChain.
Concluzie
Pentru a implementa logica ReAct pentru lucrul cu depozitul de documente în LangChain, instalați modulele sau cadrele pentru construirea modelului de limbaj. După aceea, configurați mediul pentru OpenAI pentru a configura LLM și a încărca modelul din depozitul de documente pentru a implementa logica ReAct. Acest ghid a elaborat despre implementarea logicii ReAct pentru lucrul cu depozitul de documente.