Chilă (Knowledge Extraction based on Evolutionary Learning) este un instrument software bazat pe Java care este specializat în implementarea algoritmilor evolutivi. Deoarece este o sursă deschisă, oferă o mare varietate de algoritmi de descoperire a cunoștințelor care pot fi utilizați în experimente care alimentează comunitatea de extragere și analiză a datelor. Oferă o interfață grafică simplă și ușor de utilizat, care scade semnificativ complexitatea generală a acestui instrument. Cele mai multe instrumente similare de pe piață impun utilizatorilor să interacționeze cu ele prin scrierea codului, în timp ce Keel elimină această cerință oferind o interfață intuitivă care poate fi folosită atât de începători, cât și de experți.
Keel oferă o mare varietate de algoritmi diferiți bazați pe inteligență computațională, inclusiv clasificarea, regresia, extragerea caracteristicilor, analiza modelelor, gruparea și multe altele. Cu modelele principale integrate chiar în aplicația în sine, Keel este un instrument foarte util atunci când vine vorba de efectuarea de analize exploratorii de date pe seturi de date brute. Interfața sa simplă de tip drag and drop, combinată cu ușurința utilizării funcționalității, permite experimentarea rapidă și eficientă a extragerii de date atât în scopuri educaționale, cât și în scopuri de cercetare. Instrumente precum Keel cresc în popularitate datorită abordării lor simpliste a practicilor algoritmice altfel complexe.
Instalare
Există două moduri principale în care putem instala Chilă pe orice mașină Linux. Prima presupune mersul la Pagina web Keel și descărcarea software-ului de acolo. Al doilea, pe care îl vom urmări în acest ghid de instalare, ne cere să descarcăm Keel folosind wget instrument de descărcare disponibil pentru utilizatorii Linux.
1. Începem prin a obține wget pe mașina noastră Linux.
Rulați următoarea comandă pentru a descărca wget folosind apt manager de pachete:
$ sudo apt-get install wget
Veți vedea o ieșire de terminal similară:
2. Acum că avem wget instrument instalat pe mașina noastră Linux, îl folosim pentru a descărca Chilă instrument.
Acesta este legătură că trecem la wget.
Rulați următoarea comandă în terminalul dvs.:
$ wget http: // sci2s.ugr.es / chilă / software / prototipuri / openVersion / software- 2018 -04-09.zip
Ar trebui să vedeți o ieșire similară pe terminalul dvs.:
Odată ce Keel a terminat descărcarea, putem continua cu restul instalării.
3. Acum extragem fișierul comprimat pe care l-am descărcat în pasul anterior folosind instrumentul Linux Unzip.
Rulați următoarea comandă:
$ dezarhivați software- 2018 -04-09.zip
Ar trebui să vedeți o ieșire similară în terminal:
4. Navigați în folderul Keel executând următoarea comandă:
$ CD software- 2018 -04-09 / documente / experimente / CHILĂ / dist /
5. Rulați următoarea comandă pentru a începe instalarea:
$ java -borcan . / GraphInterKeel.jar
Cu aceasta, Keel ar trebui să fie disponibil pentru a fi folosit pe mașina dvs. Linux.
Manualul utilizatorului
Interacționând cu Chilă aplicarea este cu adevărat ușoară și simplă. Să începem prin a importa Setul de date Iris în spațiul nostru de lucru.
Pe măsură ce importăm datele, instrumentul ne arată gruparea generală a punctului de date din setul de date. De asemenea, ne arată diferitele clase care sunt prezente în setul de date, împreună cu informațiile de bază, cum ar fi intervalele numerice pe care aceste puncte de date se întind și varianța generală și valorile medii pe care le prezintă. Aceste informații permit utilizatorilor să înțeleagă mai bine cum să procedeze cu pregătirea datelor pentru orice fel de sarcină de analiză a datelor.
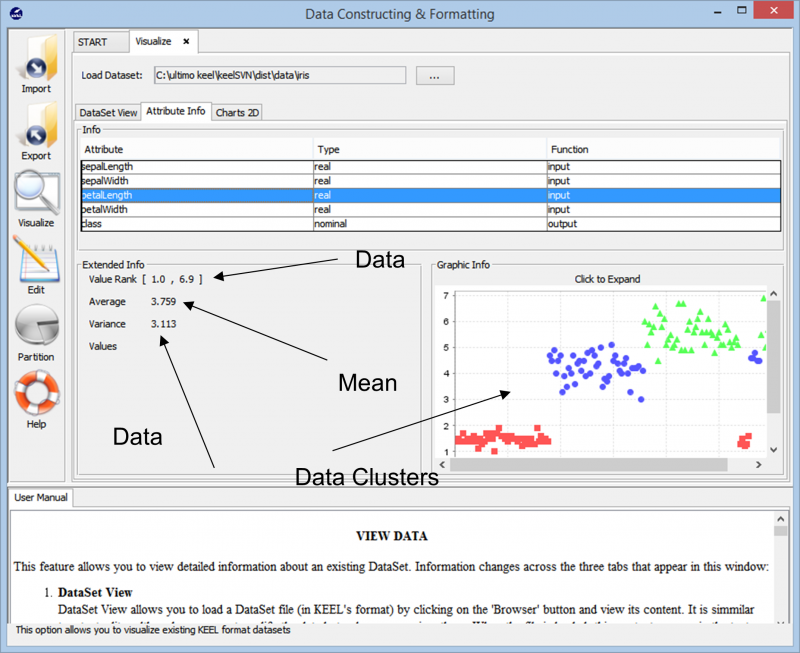
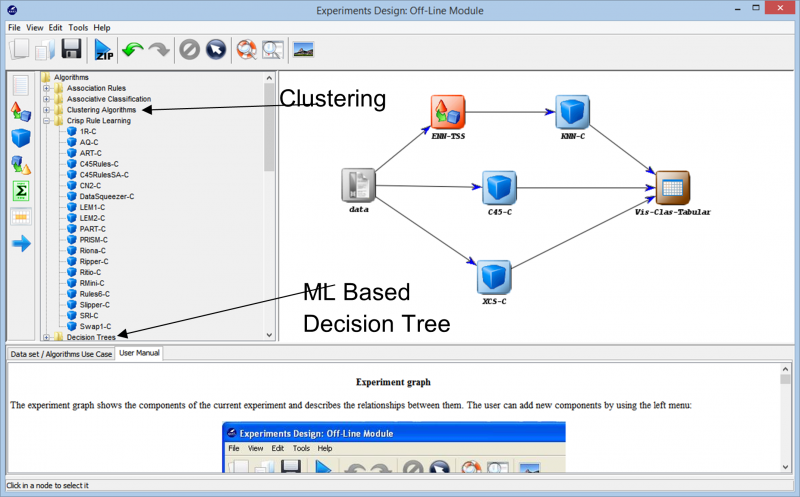
Mergând mai departe în experimentare, întâlnim diferite tehnici care pot fi utilizate pentru a crea experimentul nostru pe orice set de date. Diferiții algoritmi de învățare care pot fi utilizați pe datele noastre pot fi văzuți în imaginea următoare. În funcție de natura setului de date și de cerințele experimentului, pot fi experimentați diferiți algoritmi.
De exemplu, dacă lucrați cu date neetichetate și trebuie să găsiți asemănări între diferitele puncte de date din setul dvs. de date, utilizarea unui algoritm de grupare din diferitele opțiuni diferite disponibile vă poate ajuta să înțelegeți mai bine punctele de date. Acest lucru vă ajută în cele din urmă să etichetați și să clasificați punctele de date, astfel încât experimentul să poată fi construit folosind algoritmi de învățare supravegheată mai cuprinzătoare.
Concluzie
The Chilă platforma pentru analiza datelor este o resursă bună atât pentru cercetare, cât și în scopuri educaționale. Interfața grafică de utilizator ușor de utilizat îi ajută pe utilizatori să înțeleagă mai bine cerințele datelor, împreună cu furnizarea de referințe logice la tehnici și algoritmi folositori care îi ajută în continuare pe utilizatori în fluxurile lor de lucru. Având o gamă largă de algoritmi diferiți care se încadrează în diferitele categorii și tehnici algoritmice, permite utilizatorilor să experimenteze cu numeroase direcții logice și să compare aceste rezultate, astfel încât să poată fi atinsă cea mai optimă soluție pentru orice problemă.
Abordarea Keel cu drag și plasare fără cod pentru extragerea datelor îi ajută chiar și pe începători să lucreze fără efort cu modele cuprinzătoare de inteligență computațională. Acest lucru oferă informații despre seturi de date complexe și, prin urmare, derivă inferențe utile care ajută la rezolvarea problemelor din lumea reală.