Schiță rapidă
Această postare va demonstra următoarele:
- Cum să adăugați memorie la agentul OpenAI Functions în LangChain
- Pasul 1: Instalarea cadrelor
- Pasul 2: Configurarea Mediilor
- Pasul 3: Importarea bibliotecilor
- Pasul 4: Construirea bazei de date
- Pasul 5: Încărcarea bazei de date
- Pasul 6: Configurarea modelului de limbă
- Pasul 7: Adăugarea memoriei
- Pasul 8: Inițializarea agentului
- Pasul 9: Testarea agentului
- Concluzie
Cum să adăugați memorie la agentul de funcții OpenAI în LangChain?
OpenAI este o organizație de Inteligență Artificială (AI) care a fost înființată în 2015 și a fost o organizație non-profit la început. Microsoft a investit o mulțime de avere din 2020, deoarece procesarea limbajului natural (NLP) cu IA a crescut cu chatbot și modele de limbaj.
Crearea agenților OpenAI le permite dezvoltatorilor să obțină rezultate mai lizibile și mai precise de pe internet. Adăugarea de memorie agenților le permite să înțeleagă mai bine contextul chat-ului și să stocheze conversațiile anterioare în memoria lor. Pentru a afla procesul de adăugare a memoriei la agentul de funcții OpenAI în LangChain, parcurgeți următorii pași:
Pasul 1: Instalarea cadrelor
Mai întâi de toate, instalați dependențele LangChain din „langchain-experimental” framework folosind următorul cod:
pip install langchain - experimental
Instalați „Google-search-results” modul pentru a obține rezultatele căutării de pe serverul Google:
pip instalează google - căutare - rezultate 
De asemenea, instalați modulul OpenAI care poate fi folosit pentru a construi modelele de limbaj în LangChain:
pip install openai 
Pasul 2: Configurarea Mediilor
După obținerea modulelor, configurați mediile utilizând cheile API din OpenAI și SerpAPi conturi:
import tuimport getpass
tu. aproximativ [ „OPENAI_API_KEY” ] = getpass. getpass ( „Cheie API OpenAI:” )
tu. aproximativ [ „SERPAPI_API_KEY” ] = getpass. getpass ( „Cheia API Serpapi:” )
Executați codul de mai sus pentru a introduce cheile API pentru accesarea ambelor medii și apăsați enter pentru a confirma:
Pasul 3: Importarea bibliotecilor
Acum că configurarea este completă, utilizați dependențele instalate din LangChain pentru a importa bibliotecile necesare pentru construirea memoriei și a agenților:
din langchain. lanţuri import LLMathChaindin langchain. llms import OpenAI
#get bibliotecă pentru a căuta de pe Google pe internet
din langchain. utilitati import SerpAPIWrapper
din langchain. utilitati import SQLDatabase
din langchain_experimental. sql import SQLDatabaseChain
#get bibliotecă pentru a construi instrumente pentru inițializarea agentului
din langchain. agenţi import AgentType , Instrument , initialize_agent
din langchain. chat_models import ChatOpenAI
Pasul 4: Construirea bazei de date
Pentru a continua cu acest ghid, trebuie să construim baza de date și să ne conectăm la agent pentru a extrage răspunsuri din aceasta. Pentru a construi baza de date, este necesar să descărcați SQLite folosind aceasta ghid și confirmați instalarea folosind următoarea comandă:
sqlite3Rularea comenzii de mai sus în Terminal Windows afișează versiunea instalată de SQLite (3.43.2):
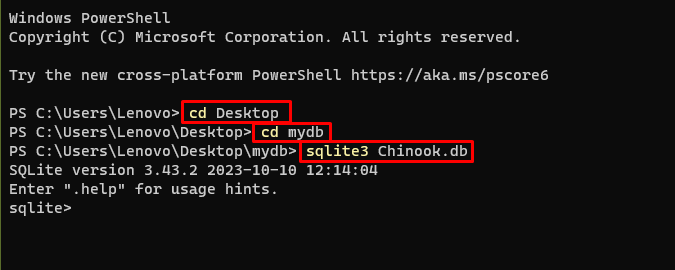
După aceea, mergeți pur și simplu la directorul de pe computer unde va fi construită și stocată baza de date:
cd Desktopcd mydb
sqlite3 Chinook. db
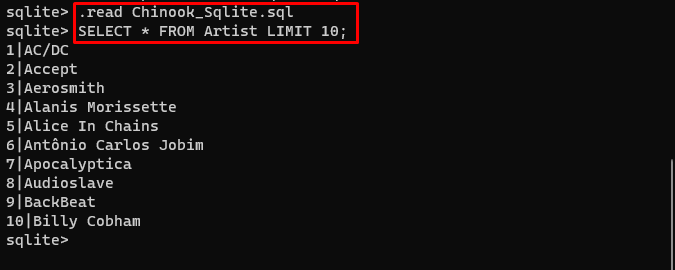
Utilizatorul poate descărca pur și simplu conținutul bazei de date de pe aceasta legătură în director și executați următoarea comandă pentru a construi baza de date:
. citit Chinook_Sqlite. sqlSELECTAȚI * DE LA LIMITĂ DE ARTIST 10 ;
Baza de date a fost construită cu succes și utilizatorul poate căuta date din ea folosind diferite interogări:
Pasul 5: Încărcarea bazei de date
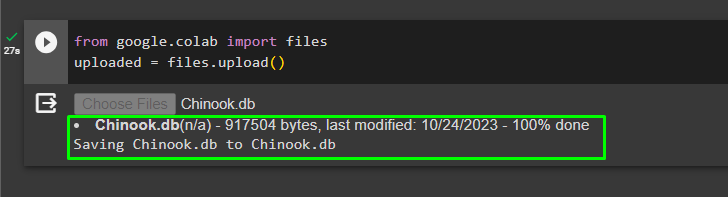
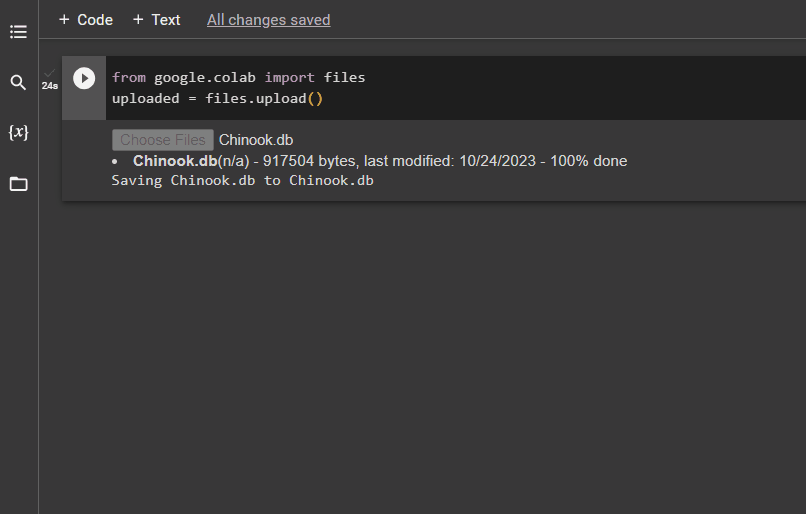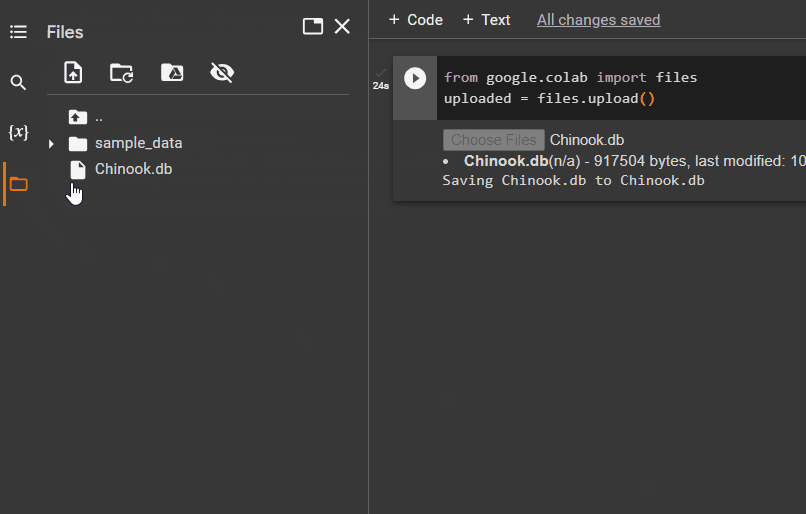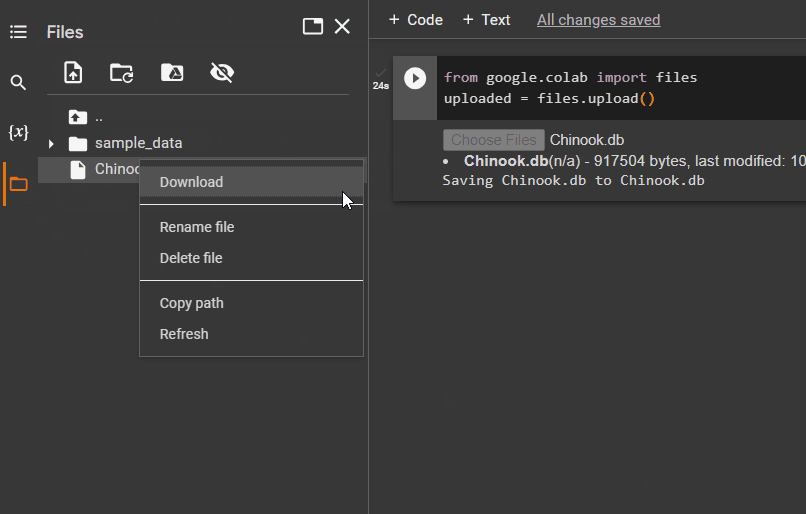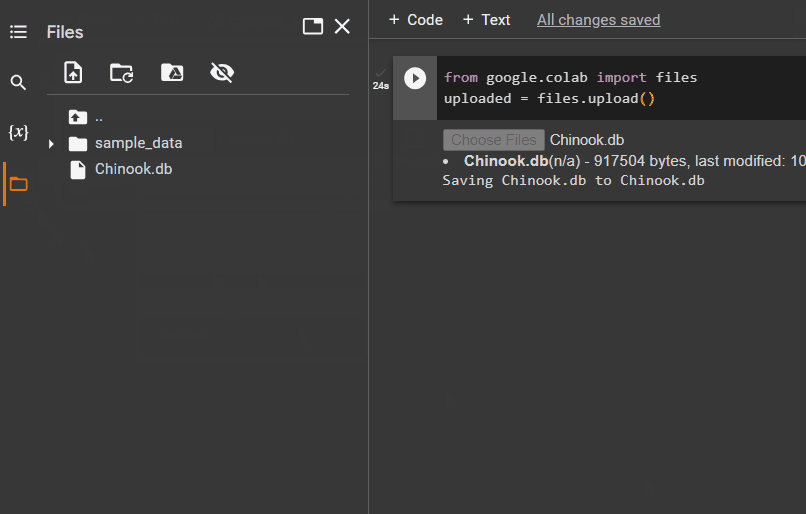
Odată ce baza de date este construită cu succes, încărcați fișierul „.db” fișier către Google Collaboratory utilizând următorul cod:
de la google. colab import fişiereîncărcat = fişiere. încărcați ( )
Alegeți fișierul din sistemul local făcând clic pe 'Alege fisierele' butonul după executarea codului de mai sus:
Odată ce fișierul este încărcat, pur și simplu copiați calea fișierului care va fi folosită în pasul următor:
Pasul 6: Configurarea modelului de limbă
Construiți modelul de limbaj, lanțurile, instrumentele și lanțurile folosind următorul cod:
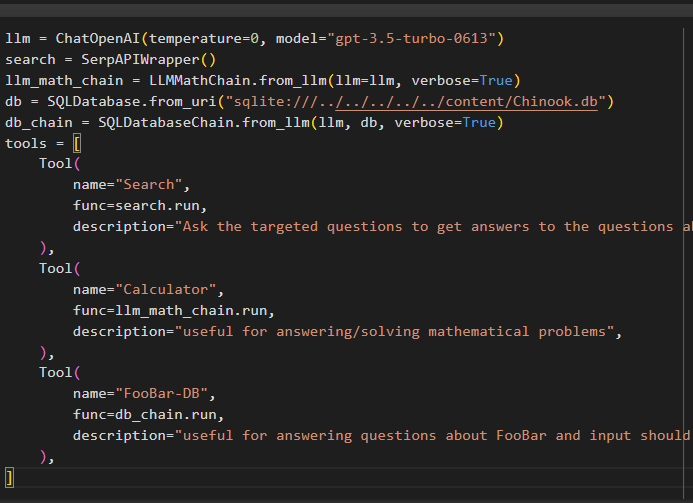
llm = ChatOpenAI ( temperatura = 0 , model = „gpt-3.5-turbo-0613” )căutare = SerpAPIWrapper ( )
llm_math_chain = LLMathChain. de la_llm ( llm = llm , verboroasă = Adevărat )
db = SQLDatabase. din_uri ( „sqlite:///../../../../../content/Chinook.db” )
db_chain = SQLDatabaseChain. de la_llm ( llm , db , verboroasă = Adevărat )
unelte = [
Instrument (
Nume = 'Căutare' ,
func = căutare. alerga ,
Descriere = „Puneți întrebările vizate pentru a obține răspunsuri la întrebările despre afaceri recente” ,
) ,
Instrument (
Nume = 'Calculator' ,
func = llm_math_chain. alerga ,
Descriere = „util pentru a răspunde/rezolva probleme matematice” ,
) ,
Instrument (
Nume = „FooBar-DB” ,
func = db_chain. alerga ,
Descriere = „utilă pentru a răspunde la întrebări despre FooBar și intrarea ar trebui să fie sub forma unei întrebări care să conțină context complet” ,
) ,
]
- The llm variabila conține configurațiile modelului de limbaj folosind metoda ChatOpenAI() cu numele modelului.
- Cautarea variabila conține metoda SerpAPIWrapper() pentru a construi instrumentele pentru agent.
- Construiește llm_math_chain pentru a obține răspunsurile legate de domeniul Matematică folosind metoda LLMMathChain().
- Variabila db conține calea fișierului care are conținutul bazei de date. Utilizatorul trebuie să schimbe doar ultima parte care este „conținut/Chinook.db” a căii păstrând „sqlite:///../../../../../” aceeași.
- Construiți un alt lanț pentru a răspunde la întrebări din baza de date folosind db_chain variabil.
- Configurați instrumente precum căutare , calculator , și FooBar-DB pentru căutarea răspunsului, răspunsul la întrebări de matematică și, respectiv, la interogări din baza de date:
Pasul 7: Adăugarea memoriei
După configurarea funcțiilor OpenAI, pur și simplu construiți și adăugați memoria la agent:
din langchain. solicitări import MesajePlaceholderdin langchain. memorie import ConversationBufferMemory
agent_kwargs = {
„extra_prompt_messages” : [ MesajePlaceholder ( nume_variabilă = 'memorie' ) ] ,
}
memorie = ConversationBufferMemory ( cheie_memorie = 'memorie' , return_messages = Adevărat )
Pasul 8: Inițializarea agentului
Ultima componentă care trebuie construită și inițializată este agentul, care conține toate componentele llm , instrument , OPENAI_FUNCTIONS , și altele care urmează să fie utilizate în acest proces:
agent = initialize_agent (unelte ,
llm ,
agent = AgentType. OPENAI_FUNCTIONS ,
verboroasă = Adevărat ,
agent_kwargs = agent_kwargs ,
memorie = memorie ,
)
Pasul 9: Testarea agentului
În cele din urmă, testați agentul inițiind chat-ul folosind „ Bună ” mesaj:
agent. alerga ( 'Bună' ) 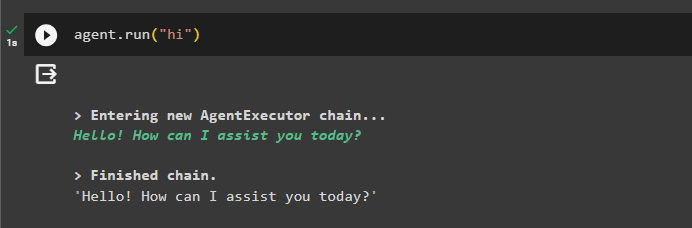
Adăugați câteva informații în memorie rulând agentul cu acesta:
agent. alerga ( „Numele meu este John Snow” ) 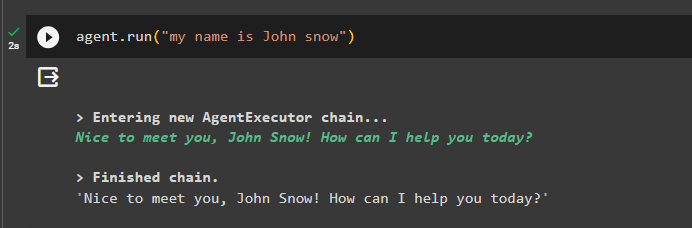
Acum, testați memoria punând întrebarea despre conversația anterioară:
agent. alerga ( 'care este numele meu' )Agentul a răspuns cu numele preluat din memorie, astfel încât memoria rulează cu succes cu agentul:
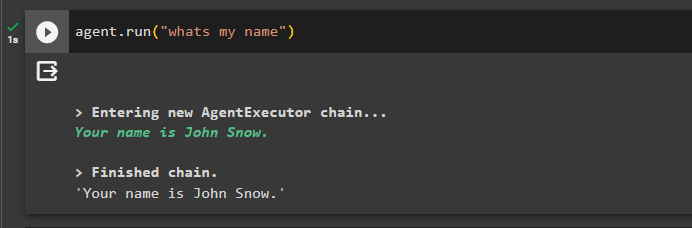
Asta este tot pentru acum.
Concluzie
Pentru a adăuga memorie la agentul de funcții OpenAI în LangChain, instalați modulele pentru a obține dependențele pentru importarea bibliotecilor. După aceea, pur și simplu construiți baza de date și încărcați-o în blocnotesul Python, astfel încât să poată fi utilizat cu modelul. Configurați modelul, instrumentele, lanțurile și baza de date înainte de a le adăuga la agent și de a le inițializa. Înainte de a testa memoria, construiți memoria folosind ConversationalBufferMemory() și adăugați-o la agent înainte de a o testa. Acest ghid a explicat cum să adăugați memorie la agentul de funcții OpenAI în LangChain.