Această postare acoperă partiționarea PostgreSQL. Vom discuta despre diferitele opțiuni de partiționare pe care le puteți utiliza și vom oferi exemple despre cum să le folosiți pentru o mai bună înțelegere.
Cum se creează partițiile PostgreSQL
Orice bază de date poate conține numeroase tabele cu mai multe intrări. Pentru o gestionare ușoară, ar trebui să partiționați tabelele, ceea ce este o rutină grozavă și recomandată de depozit de date pentru optimizarea bazei de date și pentru a ajuta la fiabilitate. Puteți crea diferite partiții, inclusiv lista, intervalul și hash. Să discutăm fiecare în detaliu.
1. Listă de partiţionare
Înainte de a lua în considerare orice partiționare, trebuie să creăm tabelul pe care îl vom folosi pentru partiții. Când creați tabelul, urmați sintaxa dată pentru toate partițiile:
CREATE TABLE table_name(column1 data_type, column2 data_type) PARTITION BY
„Nume_tabel” este numele tabelului dvs. alături de diferitele coloane pe care le va avea tabelul și tipurile de date ale acestora. Pentru „partition_key”, este coloana prin care va avea loc partiţionarea. De exemplu, următoarea imagine arată că am creat tabelul „cursuri” cu trei coloane. Mai mult, tipul nostru de partiționare este LIST și selectăm coloana facultății ca cheie de partiționare:

Odată creat tabelul, trebuie să creăm diferitele partiții de care avem nevoie. Pentru aceasta, procedați cu următoarea sintaxă:
CREATE TABLE partition_table PARTITION OF main_table FOR VALUES IN (VALUE);De exemplu, primul exemplu din imaginea următoare arată că am creat un tabel de partiții numit „Fset” care deține toate valorile din coloana „facultate” pe care am selectat-o ca cheie de partiție a cărei valoare este „FSET”. Am folosit o logică similară pentru celelalte două partiții pe care le-am creat.
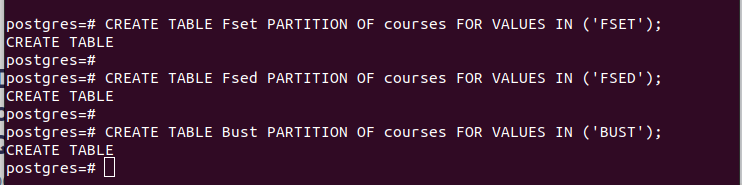
Odată ce aveți partițiile, puteți introduce valorile în tabelul principal pe care l-am creat. Fiecare valoare pe care o inserați se potrivește cu partiționarea respectivă pe baza valorilor din cheia de partiție pe care ați selectat-o.
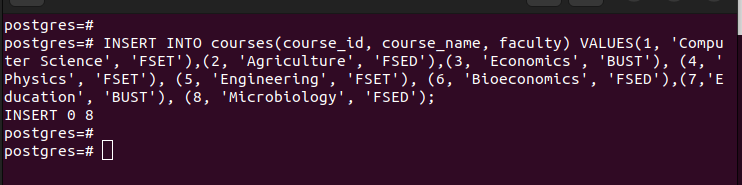
Dacă listăm toate intrările din tabelul principal, putem vedea că are toate intrările pe care le-am introdus.
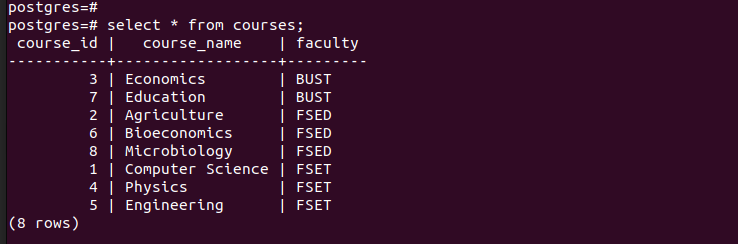
Pentru a verifica dacă am creat cu succes partițiile, să verificăm înregistrările din fiecare dintre partițiile create.
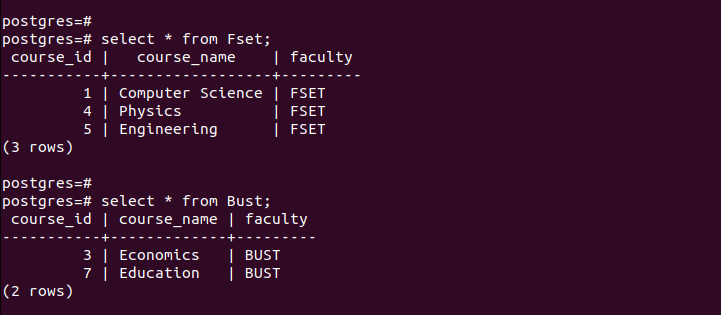
Observați cum fiecare tabel partiționat conține doar intrările care corespund criteriilor care sunt definite la partiționare. Așa funcționează partiționarea după listă.
2. Partiționarea intervalului
Un alt criteriu pentru crearea partițiilor este utilizarea opțiunii RANGE. Pentru aceasta, trebuie să specificăm valorile de început și de sfârșit de utilizat pentru interval. Utilizarea acestei metode este ideală atunci când lucrați cu curmale.
Sintaxa sa pentru crearea tabelului principal este următoarea:
CREATE TABLE table_name(column1 data_type, column2 data_type) PARTITION BY RANGE (cheie_partiție);Am creat tabelul „cust_orders” și l-am specificat pentru a folosi data ca „partition_key”.

Pentru a crea partițiile, utilizați următoarea sintaxă:
CREATE TABLE partition_table PARTIȚIA tabelului_principal PENTRU VALORI DE LA (start_value) TO (end_value);Am definit partițiile noastre să funcționeze trimestrial folosind coloana „data”.
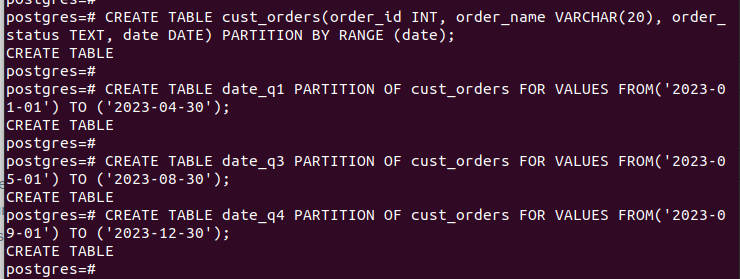
După crearea tuturor partițiilor și inserarea datelor, așa arată tabelul nostru:
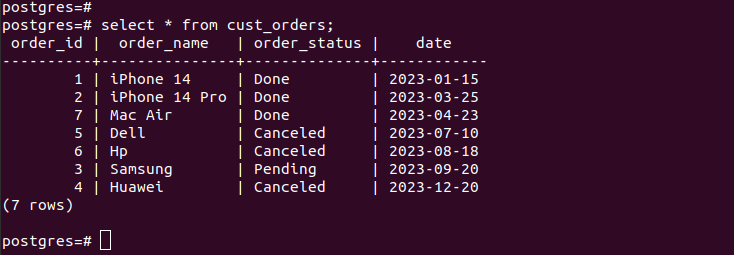
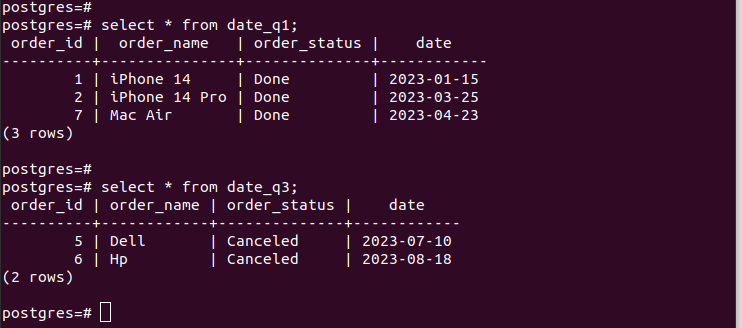
Dacă verificăm intrările din partițiile create, verificăm că partiționarea noastră funcționează și avem doar înregistrările adecvate conform criteriilor de partiționare pe care le-am specificat. Pentru toate intrările noi pe care le adăugați în tabel, acestea sunt adăugate automat la partiția respectivă.
3. Hash Partitioning
Ultimul criteriu de partiționare pe care îl vom discuta este utilizarea hash. Să creăm rapid tabelul principal folosind următoarea sintaxă:
CREATE TABLE table_name(column1 data_type, column2 data_type) PARTITION BY HASH (cheie_partiție); 
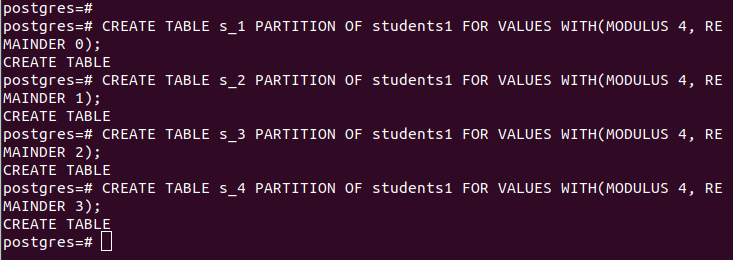
Când partiționați cu hash, trebuie să furnizați modulul și restul, rândurile urmând să fie împărțite la valoarea hash a „partition_key” specificată. Pentru cazul nostru, folosim un modul de 4.
Sintaxa noastră este următoarea:
CREATE TABLE partition_table PARTIȚIA tabelului_principal PENTRU VALORI CU (MODUL num1, REMAINDER num2);Partițiile noastre sunt după cum urmează:
Pentru „main_table”, acesta conține intrările care sunt afișate în continuare:
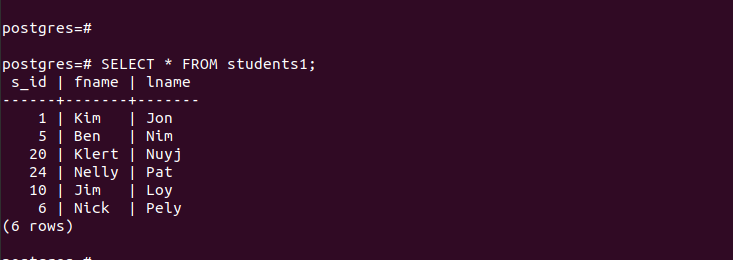
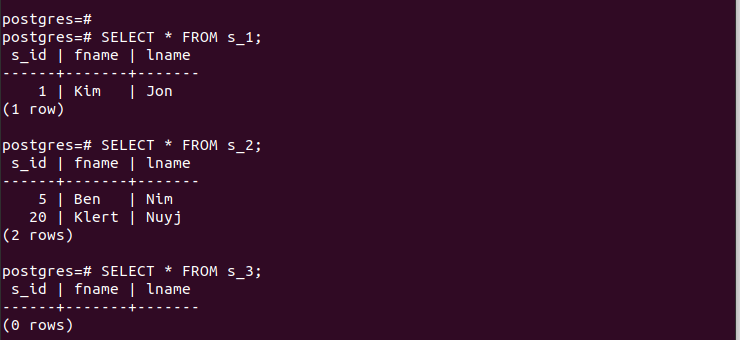
Pentru partițiile create, putem accesa rapid intrările acestora și putem verifica dacă partiționarea noastră funcționează.
Concluzie
Partițiile PostgreSQL sunt o modalitate utilă de optimizare a bazei de date pentru a economisi timp și pentru a spori fiabilitatea. Am discutat în detaliu despre partiţionare, inclusiv despre diferitele opţiuni disponibile. Mai mult, am oferit exemple despre cum să implementăm partițiile. Încercați-le!