„Pandas” este un instrument de înaltă performanță pentru mediul Python. Este un cod sursă „deschis” pentru analiza datelor. Metoda de îmbinare a panda și de îmbinare a panda sunt utilizate pentru unirea celor două cadre de date într-un singur cadru de date. În ambele metode de panda, diferența este că funcția „join” panda se alătură cadrului de date folosind un index. În timp ce funcția „merge” panda se alătură cadrului de date folosind indexul și metoda coloanei în care putem selecta singuri coloana dorită. Metoda de îmbinare a panda este folosită mai ales în comparație cu metoda de îmbinare a panda. Software-ul pe care îl vom folosi pentru implementare este software-ul „spyder”, care se află în mediul python, care ne va oferi beneficii pentru implementarea codului metodei pandas join() și funcției metodei pandas merge().
Sintaxa metodei Pandas Join().
„df1. a te alatura ( df2 ) ”„df” din sintaxa de mai sus este abrevierea „dataframe”. Există două cadre de date în sintaxă cu funcția „dot join”, care este pentru apelarea metodei. Este metoda panda de unire a două cadre de date. Funcționează folosind indexul pentru a combina cadrele de date într-unul singur.
Sintaxa metodei Pandas Merge().
„df1. combina ( df2 , pe = „nume_coloană” ) ”Sintaxa metodei de îmbinare Pandas are două cadre de date ca „df1” și „df2”. Funcția „imbinare puncte” apelează la metoda de unire a ambelor cadre de date cu aspectul coloanelor inversate.
Vom acoperi următoarele moduri de a combina două cadre de date pentru a utiliza metodele de îmbinare panda și îmbinare panda:
- Metoda Pandas Join se suprapune.
- Panda se alătură metodei folosind o resetare a indexului.
- Metoda de îmbinare Pandas (coloana „stânga și dreapta”).
- Metoda de îmbinare Pandas explicită.
Crearea cadrelor de date pentru implementarea metodei Pandas Merge și Pandas Join
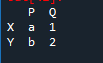
În primul rând, trebuie să creăm un cadru de date. Pentru asta, vom folosi instrumentul „spyder”. După deschiderea acestuia, începeți să scrieți codul. Importați panda ca „pd” pentru asociația bibliotecii panda. Avem variabilele cadru de date ca „x”, „y”, „p” și „q în mod corespunzător și „a” cu valorile „1” și „b” cu valoarea atribuită ca „2”.

Ieșirea este un „df” creat cu valorile atribuite. O putem face la fel de mare cât sunt datele.
Crearea unui alt cadru de date
Trebuie să facem un alt cadru de date, pentru a înțelege clar metodele de alăturare și fuziune a pandalor. Aici, „df” a creat la fel ca „df” de mai sus, doar valorile variabilelor alocate sunt diferite. Avem „h”, „j”, „s” și „d”, în timp ce atribuiți valorile „b” cu valoarea „8” și „Y” cu valoarea „3”.

Ieșirea arată un simplu „df” creat.

Exemplul # 01: Metoda de alăturare Pandas (suprapunere)
Acum, vom vedea cum să unim două cadre de date cu metoda Pandas join. Pentru această metodă, putem alege coloana la care dorim să lucrăm din cadrul de date. Am luat exemplul cu coloana suprapusă „stânga” din „df”, astfel încât să putem remedia acest lucru cu „sufixul” pentru a depăși suprapunerea datelor. Aici, variabilele utilizate sunt „x”, „z”, „v”, „d”. „p”, „o”, „l” și „y” cu valorile atribuite ca „3”, „6”, „7” și „9”. „.join” apelează metoda, cu aliniere setat la stânga join cu sufixul „df” din dreapta. ”. „Sufixul” folosit în cod se datorează faptului că în cadrul de date, există două coloane care au același nume care este „cheie” și care nu se vor suprapune cu datele.
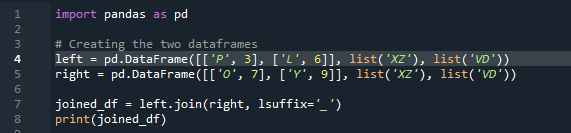
Ieșirea nu afișează date suprapuse cu metoda de unire a două „df” folosind metoda de unire panda.
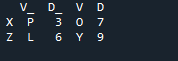
Exemplul # 02: Metoda de alăturare Pandas folosind o resetare a indexului
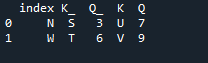
În acest exemplu, vom specifica separat coloana cu parametrul „on” pentru a fi folosită ca „cheie” în combinarea metodei care ajută la unirea celor două cadre de date. lucrul combinat se face cu acest parametru. De asemenea, indicele unuia dintre cele două „df” ar trebui să fie similar pentru a le uni. Tipuri similare de date sau date utilizate în același scop pot fi împreună pentru prelucrare. Aceasta va folosi indexul încă, folosind din dreapta. Variabilele sunt „s”, „t”, „u”, „v”, „n”, „w”, „k” și „q”. Valorile atribuite sunt „3”, „6”, „7” și „9”. „Resetarea indexului punctului” este o metodă de panda pentru a reseta indexul „df”. Indicele de resetare setează toate numerele întregi ale listei de cadru de date de la 0 până când datele din cadrul de date sunt prelungite acolo.
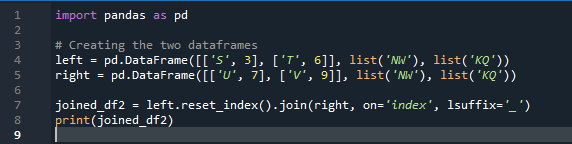
Iată rezultatul afișat cu metoda de alăturare a indexului „cheie” a panda.
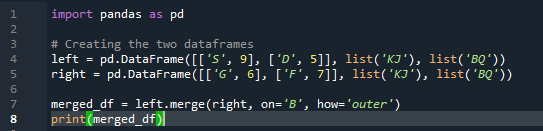
Exemplul # 03: Metoda Pandas Merge (coloana „stânga și dreapta”)
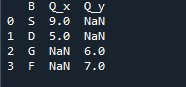
Metoda de îmbinare realizează o operație similară cu metoda de îmbinare a panda. Ambele metode sunt pentru combinarea datelor pe un cadru de date similar. Metoda de îmbinare este mai versatilă, necesitând specificarea cheii. De asemenea, îl putem specifica în coloanele din stânga și din dreapta, în funcție de activitatea cadrului de date. Variabilele din cod sunt „s”, „d”, „g”, „f”, „k”, „j”, „b” și „q”. valorile atribuite sunt „9”, „5”, „6” și „7”. Implementarea exterioară „join” se face pe ambele „df” utilizând parametrul „how” al funcției metodei pandas merge.
Ieșirea pe care o vedem arată datele îmbinate ale celor două cadre de date. „NaN” reprezintă „nu un număr”, ceea ce înseamnă că acolo unde nu există niciun număr alocat în date, „NaN” arată acolo.
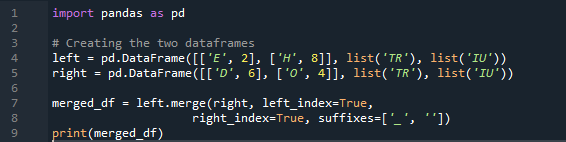
Exemplul # 04: Metoda Merge explicit
Aici, în acest exemplu, metoda de îmbinare este distrugerea indexului, iar valoarea indexului nu este asumată în cadrul de date. Vom face această metodă în funcție de munca necesară, în care specificarea explicită este de urmărire. Acesta va îmbina datele pe baza unui index din stânga sau din dreapta cu parametrul. Variabilele din acest cadru de date sunt „t”, „r”, „I”, „u”, „h”, „o”, „e” și „e”. Valorile atribuite sunt „2”, „4”, „6” și „4”. Exemplul de mai sus al metodei de îmbinare panda cu selecția coloanei în funcție de nevoi este cea mai prezentabilă și valoroasă metodă de unire a celor două cadre de date. Verificarea la sfârșitul liniei de cod despre cheia de îmbinare este unică în setul de date.
În rezultatul de mai jos, indexul nu este afișat fără index, dar funcția este efectuată pe baza indexului din dreapta și din stânga.
Concluzie
Metodele merge() și join() sunt ambele metode foarte convenabile și eficiente. Ambele funcții sunt utilizate pentru a uni cele două cadre de date separate pe același cadru de date, dar au o utilizare diferită în funcție de caz. În acest articol, am aflat diferențele cheie dintre metoda de îmbinare și îmbinare a panda. După ce am făcut exemplele și am înțeles metoda pandas join, o vom încheia știind că, dacă dorim o îmbinare mai flexibilă și în stil de bază de date, este de preferat să mergem cu metoda pandas merge. Pe de altă parte, dacă vrem să combinăm pe larg cadrul de date cu indexul, putem merge cu funcția metodei pandas join().