Acest articol va discuta despre cum să utilizați API-ul multi-get Elasticsearch pentru a prelua mai multe documente JSON pe baza ID-urilor acestora. În plus, Elasticsearch vă permite să utilizați o singură interogare de obținere pentru a prelua documentele din indici folosind doar ID-urile documentului.
Să explorăm.
Sintaxa de solicitare
Următoarea este sintaxa pentru API-ul multi-get Elasticsearch:
GET /_mget
GET /
API-ul multi-get acceptă mai mulți indici, ceea ce vă permite să preluați documentele chiar dacă acestea nu se află în același index.
Solicitarea acceptă următorii parametri de cale:
-
– Numele indexului de pe care să se recupereze documentele specificate de ID-urile lor.
De asemenea, puteți specifica ceilalți parametri de interogare, așa cum se arată:
- Preferinţă – Definește nodul sau fragmentul preferat.
- Timp real – Dacă este setată la true, operația este efectuată în timp real.
- Reîmprospăta – Forțează operația să reîmprospăteze fragmentele țintă înainte de a prelua documentele specificate.
- Dirijare – O valoare care este utilizată pentru a direcționa operațiunile către un anumit fragment.
- Câmpuri_magazin – Preluează câmpurile documentului stocate într-un index, mai degrabă decât în document.
- _sursă – O valoare booleană care definește dacă cererea trebuie să returneze câmpul _source sau nu.
Interogarea necesită corpul, care include următoarele valori:
- Docs – Specifică documentele pe care doriți să le preluați. În plus, această secțiune acceptă următoarele atribute:
- _id – ID unic al documentului țintă.
- _index – Indexul care conține documentul țintă.
- Dirijare – Cheia pentru fragmentul primar al documentului.
- _sursă – Dacă este adevărat, include toate câmpurile sursă; în caz contrar, îi exclude.
- _câmpuri_stocate – Câmpurile_stocate pe care doriți să le includeți.
- Id-uri – Id-urile documentelor pe care doriți să le preluați.
Exemplul 1: Preluați mai multe documente din același index
Următorul exemplu arată cum să utilizați API-ul multi-get Elasticsearch pentru a prelua documentele cu anumite ID-uri din indexul Netflix:
curl -XGET 'http://localhost:9200/netflix/_mget' -H 'kbn-xsrf: raportare' -H 'Tip conținut: aplicație/json' -d'{
„docs”: [
{
'_id': 'T3wnVoMBck2AEzXPytlJ'
},
{
'_id': 'W3wnVoMBck2AEzXPytlJ'
}
]
}'
Solicitarea dată ar trebui să preia documentele cu ID-urile specificate din indexul Netflix. Rezultatul rezultat este așa cum se arată:
{„docs”: [
{
'_index': 'netflix',
'_id': 'T3wnVoMBck2AEzXPytlJ',
„_versiunea”: 1,
„_seq_no”: 0,
„_primary_term”: 1,
„găsit”: adevărat,
'_sursă': {
„durată”: „90 min”,
'listed_in': 'Documentare',
„country”: „Statele Unite”,
'date_added': '25 septembrie 2021',
'show_id': 's1',
„director”: „Kirsten Johnson”,
„release_year”: 2020,
„evaluare”: „PG-13”,
„descriere”: „Pe măsură ce tatăl ei se apropie de sfârșitul vieții, realizatorul Kirsten Johnson își pune în scenă moartea în moduri inventive și comice pentru a-i ajuta pe amândoi să facă față inevitabilului.”
'type': 'Film',
„title”: „Dick Johnson este mort”
}
},
{
'_index': 'netflix',
'_id': 'W3wnVoMBck2AEzXPytlJ',
„_versiunea”: 1,
„_seq_no”: 12,
„_primary_term”: 1,
„găsit”: adevărat,
'_sursă': {
„țară”: „Germania, Republica Cehă”,
'show_id': 's13',
„director”: „Christian Schwochow”,
„release_year”: 2021,
'evaluare': 'TV-MA',
„descriere”: „După ce cea mai mare parte a familiei ei este ucisă într-un atentat terorist cu bombă, o tânără este atrasă fără să știe să se alăture grupului care i-a ucis.”
'type': 'Film',
'title': 'Eu sunt Karl',
„durată”: „127 min”,
'listed_in': 'Drame, filme internaționale',
„distribuție”: „Luna Wedler, Jannis Niewöhner, Milan Peschel, Edin Hasanović, Anna Fialová, Marlon Boess, Victor Boccard, Fleur Geffrier, Aziz Dyab, Mélanie Fouché, Elizaveta Maximová”,
'date_added': '23 septembrie 2021'
}
}
]
}
De asemenea, putem simplifica solicitarea punând ID-urile documentului într-o matrice simplă, așa cum se arată în următoarele:
curl -XGET 'http://localhost:9200/netflix/_mget' -H 'kbn-xsrf: raportare' -H 'Tip conținut: aplicație/json' -d'{
'ids': ['T3wnVoMBck2AEzXPytlJ', 'W3wnVoMBck2AEzXPytlJ']
}'
Solicitarea anterioară ar trebui să efectueze o acțiune similară.
Exemplul 2: Preluați documentele din mai multe indicii
În exemplul următor, cererea preia mai multe documente din indici diferiți, după cum se arată:
curl -XGET 'http://localhost:9200/_mget' -H 'kbn-xsrf: raportare' -H 'Tip de conținut: aplicație/json' -d'{
„docs”: [
{
'_index': 'netflix',
'_id': 'T3wnVoMBck2AEzXPytlJ'
},
{
'_index': 'disney',
„_id”: „8j4wWoMB1yF5VqfaKCE4”
}
]
}'
Rezultatul rezultat este așa cum se arată:

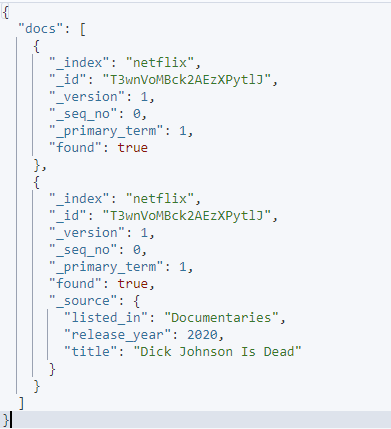
Exemplul 3: Excludeți anumite câmpuri
Putem exclude anumite câmpuri dintr-o solicitare dată utilizând parametrii source_include și source_exclude.
Un exemplu este așa cum se arată:
curl -XGET 'http://localhost:9200/_mget' -H 'kbn-xsrf: raportare' -H 'Tip de conținut: aplicație/json' -d'{
„docs”: [
{
'_index': 'netflix',
'_id': 'T3wnVoMBck2AEzXPytlJ',
„_sursă”: fals
},
{
'_index': 'netflix',
'_id': 'T3wnVoMBck2AEzXPytlJ',
'_sursă': {
„include”: [ „listed_in”, „release_year”, „title” ],
„exclude”: [ „descriere”, „tip”, „data_adăugată” ]
}
}
]
}'
Solicitarea dată utilizează sursa include și exclude pentru a specifica ce câmpuri doriți să preluați dintr-un anumit document.
Rezultatul rezultat este așa cum se arată:
Concluzie
În această postare, am discutat elementele fundamentale ale lucrului cu API-ul multi-get Elasticsearch, care vă permite să preluați mai multe documente din diverse surse pe baza ID-urilor lor. Nu ezitați să explorați celelalte documente pentru mai multe informații.
Codare fericită!