„Comma-Separated Values (CSV) este unul dintre cele mai versatile și mai ușor de utilizat formate de date. Este un format de date ușor care permite dezvoltatorilor și aplicațiilor să transfere și să analizeze date de la o sursă la alta.
Datele CSV stochează datele într-un format tabelar în care fiecare coloană este separată prin virgulă, iar o nouă înregistrare este alocată unei linii noi. Acest lucru îl face o alegere foarte bună pentru exportul bazelor de date, cum ar fi baze de date SQL, date Cassandra și multe altele.
Prin urmare, nu este surprinzător că veți întâlni un scenariu în care trebuie să importați un fișier CSV în baza de date.
Scopul acestui tutorial este să vă arate o metodă rapidă și simplă de a importa un fișier CSV în clusterul dvs. Elasticsearch folosind tabloul de bord Kibana.”
Să sărim înăuntru.
Cerințe
Înainte de a vă scufunda, asigurați-vă că aveți următoarele cerințe:
- Un cluster Elasticsearch cu stare de sănătate verde.
- Serverul Kibana conectat la clusterul dvs. Elasticsearch.
- Permisiuni suficiente pentru a gestiona indexurile din clusterul dvs.
Exemplu de fișier CSV
Ca de obicei, prima cerință este fișierul CSV sursă. Este bine să vă asigurați că datele din fișierul dvs. CSV sunt bine formatate și că nu conțin erori.
În scopuri ilustrative, vom folosi un set de date gratuit care conține filme și emisiuni TV de la Amazon Prime.
Deschideți browserul și navigați la resursa de mai jos:
https://www.kaggle.com/datasets/shivamb/amazon-prime-movies-and-tv-shows
Urmați procedura pentru a descărca setul de date pe mașina dvs. locală. Puteți extrage arhiva descărcată cu comanda:
$ dezarhivați a~ / Descărcări / archive.zip
Importați fișierul CSV
După ce aveți gata fișierul sursă, putem continua și discutăm despre cum să-l importați.
Începeți prin a merge la tabloul de bord Kibana de acasă și selectați opțiunea „încărcați un fișier”.
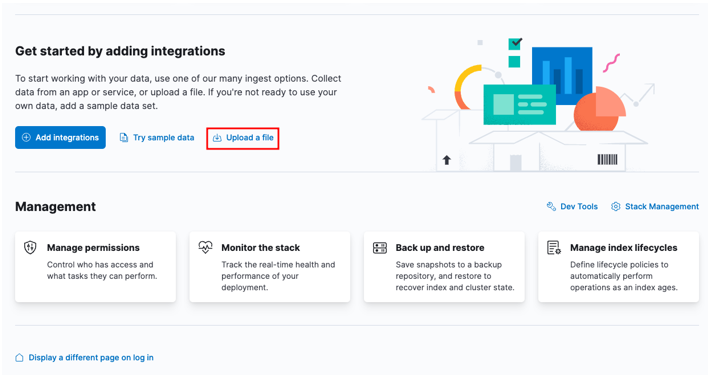
Localizați fișierul CSV țintă pe care doriți să îl importați în fereastra de lansare.
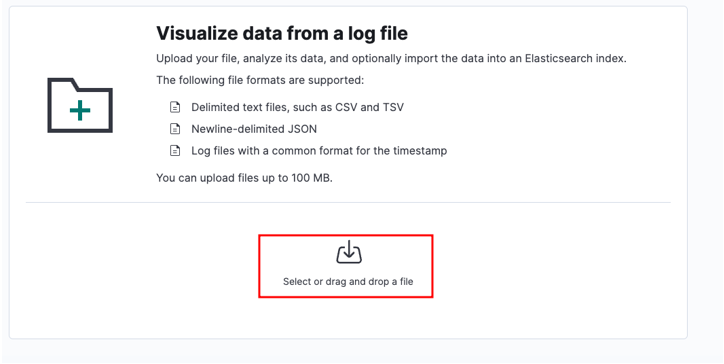
Selectați fișierul sursă și faceți clic pe încărcare.
Permiteți Elasticsearch și Kibana să analizeze fișierul încărcat. Aceasta va analiza fișierul CSV și va determina formatul datelor, câmpurile, tipurile de date etc.
NOTĂ: În funcție de configurația clusterului și de dimensiunea datelor, acest proces poate dura ceva timp. Asigurați-vă că nodul master răspunde pentru a evita expirarea timpului.
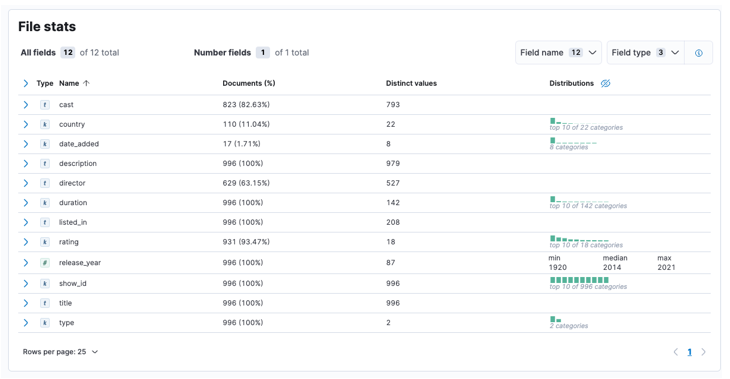
Odată ce procesul este finalizat, ar trebui să obțineți o mostră a conținutului fișierului și statisticile fișierelor, așa cum sunt analizate de Elastic.
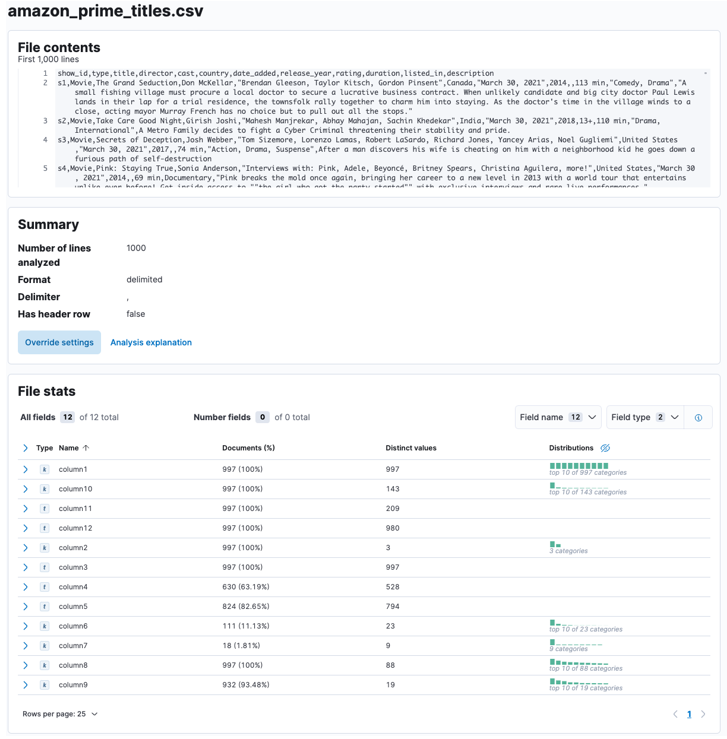
Puteți personaliza numeroși parametri, de exemplu, delimitatorul, rândurile antetului etc. De exemplu, putem personaliza rezultatul de mai sus pentru a-i spune lui Elastic că fișierul nostru CSV conține fișiere antet.
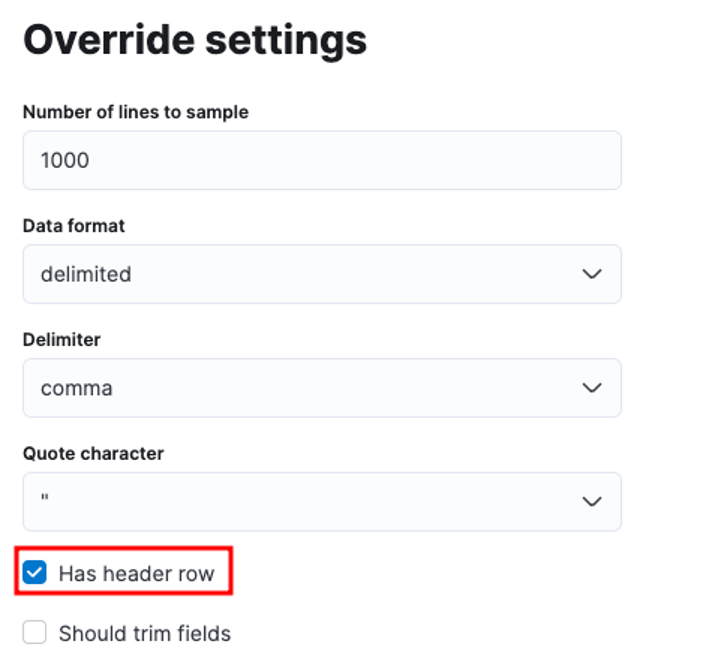
Putem apoi să facem clic pe Aplicare și să reanalizam datele. Aceasta ar trebui să formateze datele în formatul corect, inclusiv câmpurile.
Apoi, putem face clic pe import pentru a trece la tabloul de bord importat.
Aici, trebuie să creăm un index în care sunt stocate datele CSV. Puteți aloca orice nume acceptat indexului dvs.
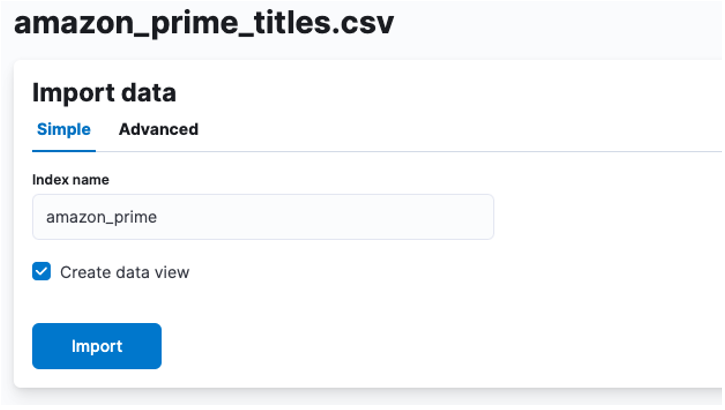
Dacă doriți să vă personalizați proprietățile indexului, cum ar fi numărul de fragmente, replici, mapări etc. Selectați opțiunea avansată și modificați setările după cum doriți.
În cele din urmă, faceți clic pe import și urmăriți cum Kibana își face „magia”. Odată finalizat, vă puteți accesa indexul fie prin API-ul Elasticsearch, fie să utilizați tabloul de bord Kibana.
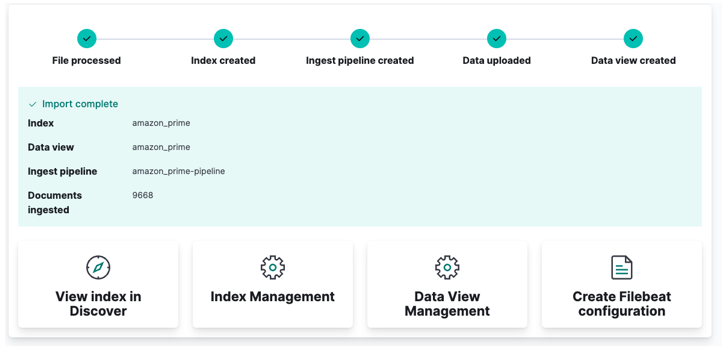
Si ai terminat!!
Concluzie
În această postare, am acoperit procesul de preluare și importare a setului de date CSV în clusterul dvs. Elasticsearch folosind tabloul de bord Kibana.
Mulțumesc pentru lectură și codare fericită!!