Acest ghid va explica cum să creați crawler-uri pentru a prelua date din compartimentul S3.
Cum se creează un crawler pentru a prelua date din S3 Bucket?
Pentru a crea un crawler în AWS, vizitați „ AWS Glue ” serviciu din tabloul de bord Amazon:
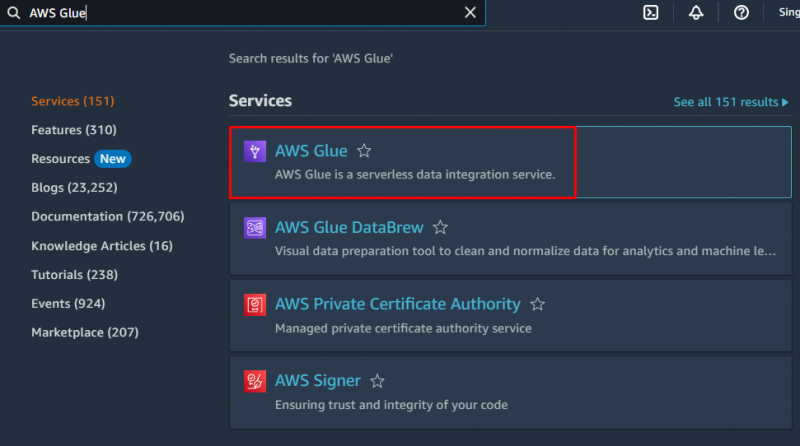
Faceți clic pe „ Baze de date ” din secțiunea Catalog de date pentru a crea o bază de date:
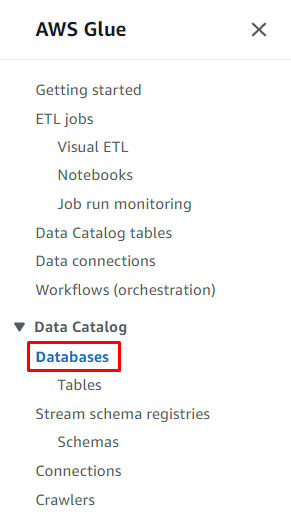
Faceți clic pe „ Adăugați baza de date butonul ” pentru a porni configurarea:
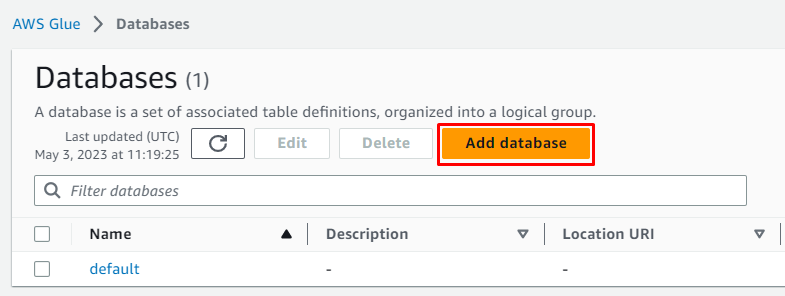
Introduceți numele bazei de date și lăsați totul ca fiind opțional înainte de a face clic pe „ Creați o bază de date butonul ”:
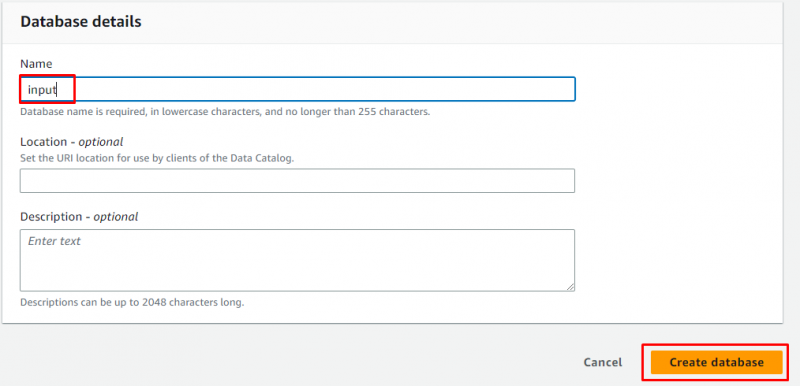
Baza de date a fost creată cu succes:
După aceea, mergeți pur și simplu la „ Crawlers ” făcând clic pe ea din panoul din stânga:
Faceți clic pe „ Creați un crawler butonul ”:

Tastați numele crawler-ului și faceți clic pe „ Următorul butonul ”:

Faceți clic pe „ Adăugați o sursă de date butonul ” pentru a selecta sursa datelor:
Pentru a verifica calea în care sunt stocate datele, vizitați serviciul S3:
Mergeți în compartimentul S3 unde sunt încărcate datele. Utilizatorul poate crea o găleată și încărcați date despre acesta din tabloul de bord AWS S3:

Faceți clic pe „ Răsfoiți S3 ” pentru a alege calea datelor:
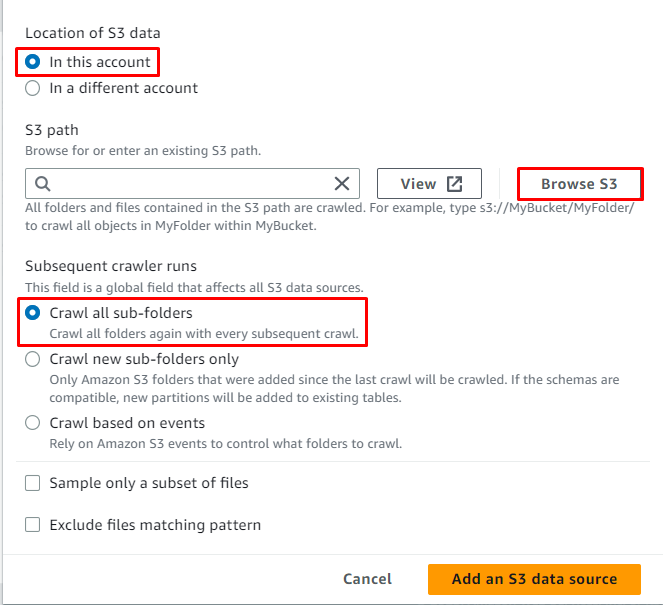
Selectați folderul care conține datele, apoi faceți clic pe „ Alege butonul ”:

Calea S3 a fost selectată, acum faceți clic pe „ Adăugați o sursă de date S3 butonul ”:

Odată ce sursa de date este adăugată, faceți clic pe butonul „ Următorul butonul ”:
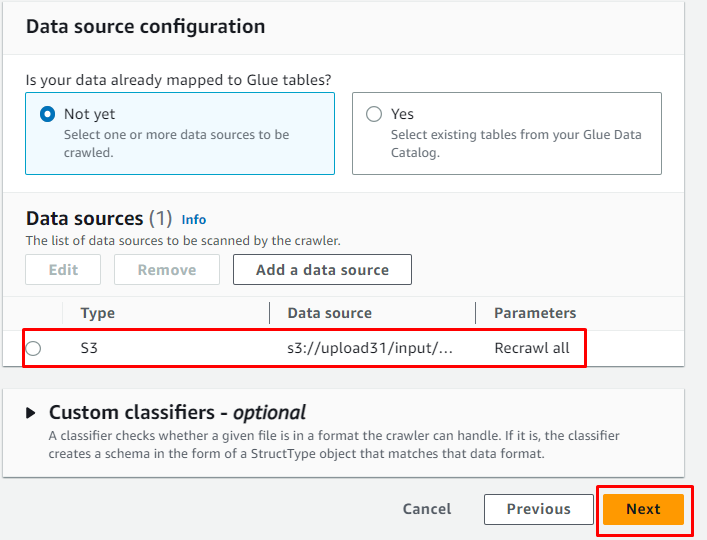
Adăugați rolul IAM și apoi faceți clic pe „ Următorul butonul ”:
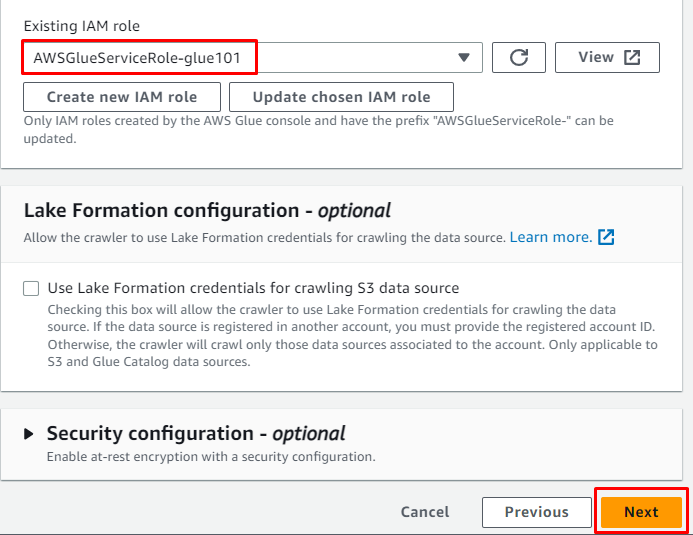
Introduceți baza de date țintă creată mai devreme și apoi introduceți numele tabelului:
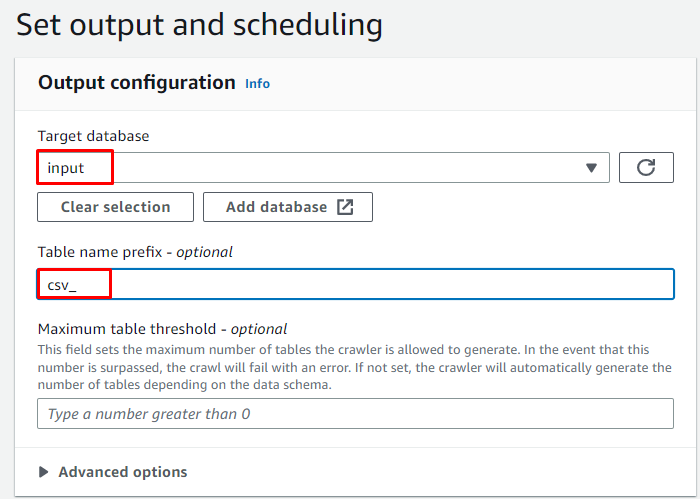
Selectați programul La cerere pentru crawler și faceți clic pe „ Următorul butonul ”:
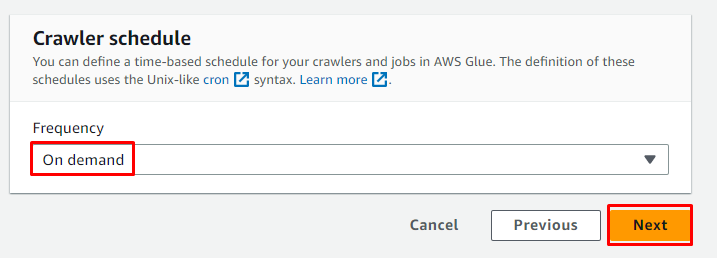
Examinați crawler-ul și faceți clic pe „ Creați un crawler butonul ”:
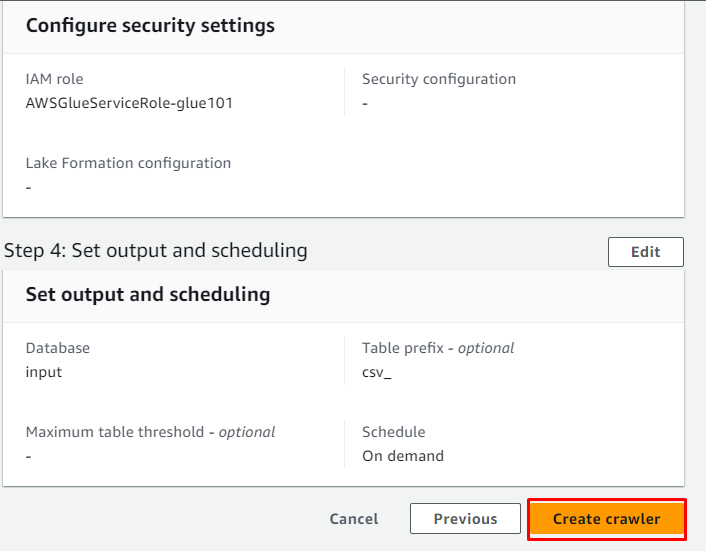
Crawler-ul a fost creat cu succes, faceți clic pe „ Alerga butonul ” după ce l-ați selectat:

Va dura câteva momente pentru a rula crawler-ul și va prelua date și va crea un tabel pentru a stoca datele:
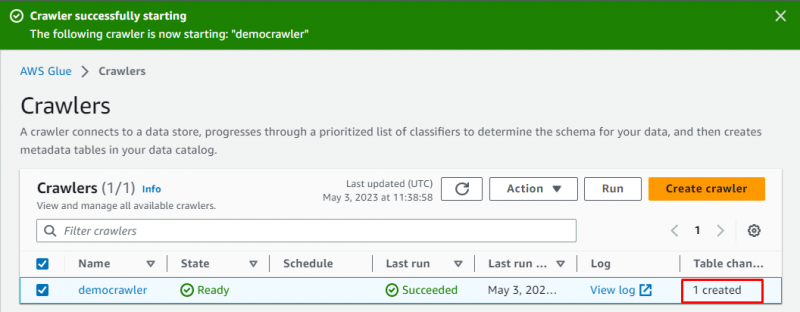
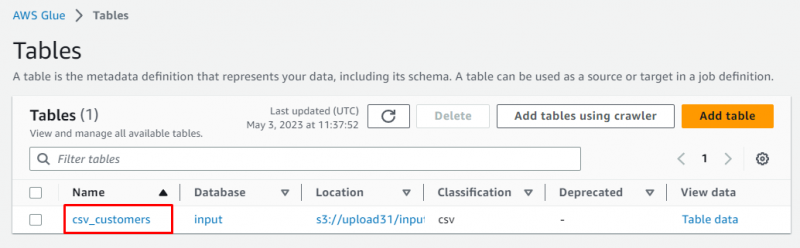
Mergeți în „ Mese ” din tabloul de bord Glue:
Selectați tabelul făcând clic pe numele acestuia:
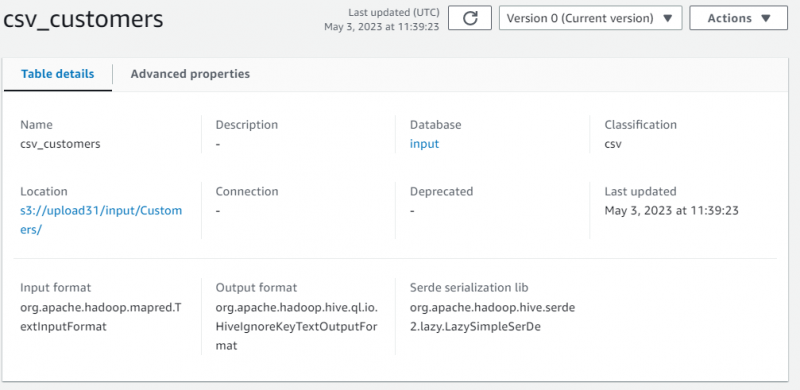
Detaliile poveștii au fost afișate conținând metadatele datelor preluate:
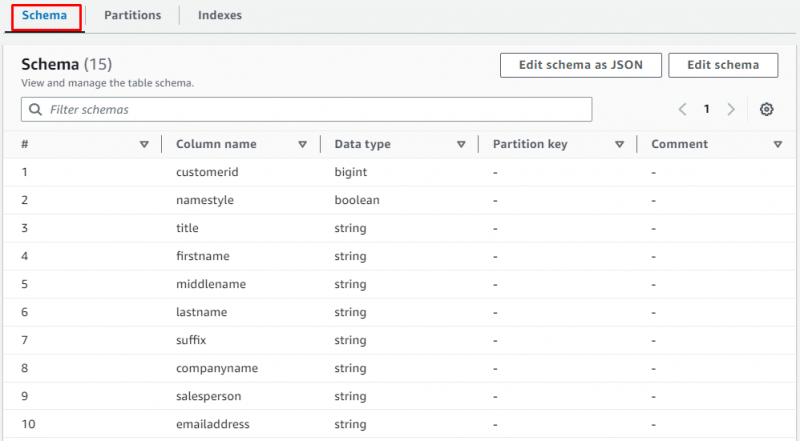
Derulați în jos în pagină și selectați secțiunea pentru a vizualiza tabelul care conține datele:
Este vorba despre crearea unui crawler pentru a prelua date din bucket-ul S3.
Concluzie
Pentru a crea un crawler pentru a prelua date din compartimentul S3, creați o bază de date pe AWS Glue în care vor fi stocate datele accesate cu crawlere. Configurați crawler-ul din tabloul de bord Glue furnizând sursa datelor (bucket S3) și baza de date țintă. Rulați crawler-ul și preluați datele din compartimentul S3 în tabelul bazei de date, așa cum a explicat în detaliu acest ghid.