Începutul limbajului C++ a avut loc în 1983, la scurt timp după aceea „Bjare Stroustrup” a lucrat cu clase în limbajul C inclusiv cu unele caracteristici suplimentare, cum ar fi supraîncărcarea operatorului. Extensiile de fișiere utilizate sunt „.c” și „.cpp”. C++ este extensibil și nu depinde de platformă și include STL, care este abrevierea Standard Template Library. Deci, în principiu, cunoscutul limbaj C++ este de fapt cunoscut ca un limbaj compilat care are fișierul sursă compilat împreună pentru a forma fișiere obiect, care atunci când sunt combinate cu un linker produc un program rulabil.
Pe de altă parte, dacă vorbim despre nivelul său, este de nivel mediu interpretând avantajul programării de nivel scăzut, cum ar fi driverele sau nucleele, și, de asemenea, aplicațiile de nivel superior precum jocurile, GUI sau aplicațiile desktop. Dar sintaxa este aproape aceeași atât pentru C, cât și pentru C++.
Componentele limbajului C++:
#include
Această comandă este un fișier antet care cuprinde comanda „cout”. Ar putea exista mai mult de un fișier antet, în funcție de nevoile și preferințele utilizatorului.
int main()
Această instrucțiune este funcția programului principal care este o condiție prealabilă pentru fiecare program C++, ceea ce înseamnă că fără această instrucțiune nu se poate executa niciun program C++. Aici „int” este tipul de date al variabilei returnate care spune despre tipul de date pe care funcția le returnează.
Declaraţie:
Variabilele sunt declarate și le sunt atribuite nume.
Declarație problemă:
Acest lucru este esențial într-un program și poate fi o buclă „while”, „for” sau orice altă condiție aplicată.
Operatori:
Operatorii sunt folosiți în programele C++ și unii sunt cruciali pentru că sunt aplicați condițiilor. Câțiva operatori importanți sunt &&, ||, !, &, !=, |, &=, |=, ^, ^=.
C++ Intrare Ieșire:
Acum, vom discuta despre capacitățile de intrare și ieșire în C++. Toate bibliotecile standard utilizate în C++ oferă capacități maxime de intrare și ieșire care sunt realizate sub forma unei secvențe de octeți sau sunt în mod normal legate de fluxuri.
Flux de intrare:
În cazul în care octeții sunt transmisi în flux de pe dispozitiv în memoria principală, acesta este fluxul de intrare.
Flux de ieșire:
Dacă octeții sunt transmisi în flux în direcția opusă, acesta este fluxul de ieșire.
Un fișier antet este folosit pentru a facilita intrarea și ieșirea în C++. Este scris ca
Exemplu:
Vom afișa un șir de mesaj folosind un șir de caractere.
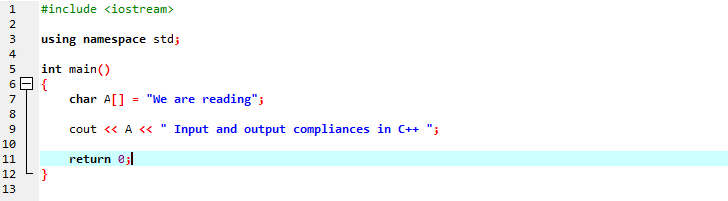
În prima linie, includem „iostream” care are aproape toate bibliotecile esențiale de care am putea avea nevoie pentru execuția unui program C++. În rândul următor, declarăm un spațiu de nume care oferă domeniul de aplicare pentru identificatori. După apelarea funcției principale, inițializam o matrice de tip caracter care stochează mesajul șir și „cout” îl afișează prin concatenare. Folosim „cout” pentru afișarea textului pe ecran. De asemenea, am luat o variabilă „A” având o matrice de tip de date caracter pentru a stoca un șir de caractere și apoi am adăugat atât mesajul matrice de-a lungul mesajului static folosind comanda „cout”.
Ieșirea generată este prezentată mai jos:

Exemplu:
În acest caz, am reprezenta vârsta utilizatorului într-un mesaj simplu șir.
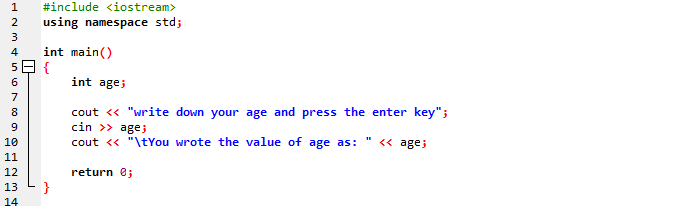
În primul pas includem biblioteca. După aceea, folosim un spațiu de nume care ar oferi domeniul de aplicare pentru identificatori. În pasul următor, numim principal() funcţie. După care, inițializam vârsta ca o variabilă „int”. Folosim comanda „cin” pentru introducere și comanda „cout” pentru ieșirea mesajului șir simplu. „cin” introduce valoarea vârstei de la utilizator, iar „cout” o afișează în celălalt mesaj static.

Acest mesaj este afișat pe ecran după executarea programului, astfel încât utilizatorul să poată obține vârsta și apoi apăsați ENTER.

Exemplu:
Aici, demonstrăm cum să tipăriți un șir folosind „cout”.

Pentru a tipări un șir, includem inițial o bibliotecă și apoi spațiul de nume pentru identificatori. The principal() funcția este numită. În plus, imprimăm o ieșire șir folosind comanda „cout” cu operatorul de inserare care afișează apoi mesajul static pe ecran.

Tipuri de date C++:
Tipurile de date în C++ este un subiect foarte important și cunoscut pe scară largă, deoarece este baza limbajului de programare C++. În mod similar, orice variabilă utilizată trebuie să fie de un tip de date specificat sau identificat.
Știm că pentru toate variabilele, folosim tipul de date în timpul declarației pentru a limita tipul de date care trebuia restaurat. Sau, am putea spune că tipurile de date spun întotdeauna unei variabile tipul de date pe care o stochează. De fiecare dată când definim o variabilă, compilatorul alocă memoria pe baza tipului de date declarat, deoarece fiecare tip de date are o capacitate diferită de stocare a memoriei.
Limbajul C++ ajută diversitatea tipurilor de date, astfel încât programatorul să poată selecta tipul de date adecvat de care ar putea avea nevoie.
C++ facilitează utilizarea tipurilor de date menționate mai jos:
- Tipuri de date definite de utilizator
- Tipuri de date derivate
- Tipuri de date încorporate
De exemplu, următoarele linii sunt date pentru a ilustra importanța tipurilor de date prin inițializarea câtorva tipuri de date comune:
int A = Două ; // valoare intreagapluti F_N = 3,66 ; // valoare în virgulă mobilă
dubla D_N = 8,87 ; // valoare dublă în virgulă mobilă
char Alfa = 'p' ; // caracter
bool b = Adevărat ; // Boolean
Câteva tipuri de date comune: ce dimensiune specifică și ce tip de informații vor stoca variabilele lor sunt prezentate mai jos:
- Char: Cu dimensiunea unui octet, va stoca un singur caracter, literă, număr sau valori ASCII.
- Boolean: Cu dimensiunea de 1 octet, va stoca și va returna valori ca fiind adevărate sau false.
- Int: Cu o dimensiune de 2 sau 4 octeți, va stoca numere întregi fără zecimale.
- Virgulă mobilă: cu dimensiunea de 4 octeți, va stoca numere fracționale care au una sau mai multe zecimale. Acest lucru este adecvat pentru stocarea a până la 7 cifre zecimale.
- Virgulă mobilă dublă: cu dimensiunea de 8 octeți, va stoca și numerele fracționale care au una sau mai multe zecimale. Acest lucru este adecvat pentru stocarea a până la 15 cifre zecimale.
- Void: Fără o dimensiune specificată, un vid conține ceva fără valoare. Prin urmare, este utilizat pentru funcțiile care returnează o valoare nulă.
- Caracter lat: cu o dimensiune mai mare de 8 biți, care are de obicei 2 sau 4 octeți, este reprezentat de wchar_t care este similar cu char și astfel stochează și o valoare de caracter.
Mărimea variabilelor menționate mai sus poate diferi în funcție de utilizarea programului sau a compilatorului.
Exemplu:
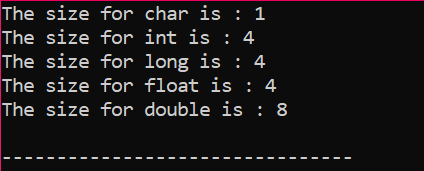
Să scriem un cod simplu în C++ care va produce dimensiunile exacte ale câtorva tipuri de date descrise mai sus:

În acest cod, integrăm biblioteca
Ieșirea este primită în octeți, așa cum se arată în figură:
Exemplu:
Aici am adăuga dimensiunea a două tipuri de date diferite.
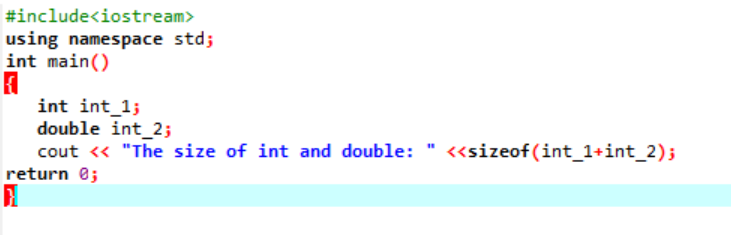
În primul rând, încorporăm un fișier antet care utilizează un „spațiu de nume standard” pentru identificatori. În continuare, cel principal() se numește funcția în care inițializam variabila „int” la început și apoi o variabilă „dublă” pentru a verifica diferența dintre dimensiunile acestor două. Apoi, dimensiunile lor sunt concatenate prin utilizarea lui dimensiunea() funcţie. Ieșirea este afișată de instrucțiunea „cout”.

Mai este un termen care trebuie menționat aici și este „Modificatori de date” . Numele sugerează că „modificatorii de date” sunt folosiți de-a lungul tipurilor de date încorporate pentru a-și modifica lungimile pe care un anumit tip de date le poate susține în funcție de nevoia sau cerințele compilatorului.
Următoarele sunt modificatorii de date care sunt accesibili în C++:
- Semnat
- Nesemnat
- Lung
- Mic de statura
Mărimea modificată și, de asemenea, intervalul corespunzător al tipurilor de date încorporate sunt menționate mai jos atunci când sunt combinate cu modificatorii tipului de date:
- Short int: având dimensiunea de 2 octeți, are o gamă de modificări de la -32.768 la 32.767
- Unsigned short int: având dimensiunea de 2 octeți, are o gamă de modificări de la 0 la 65.535
- Unsigned int: având dimensiunea de 4 octeți, are o gamă de modificări de la 0 la 4.294.967.295
- Int: având dimensiunea de 4 octeți, are o gamă de modificări de la -2.147.483.648 la 2.147.483.647
- Long int: având dimensiunea de 4 octeți, are o gamă de modificări de la -2.147.483.648 la 2.147.483.647
- Unsigned long int: având o dimensiune de 4 octeți, are o gamă de modificări de la 0 la 4.294.967,295
- Long long int: având dimensiunea de 8 octeți, are o gamă de modificări de la –(2^63) la (2^63)-1
- Unsigned long long int: având o dimensiune de 8 octeți, are o gamă de modificări de la 0 la 18.446.744.073.709.551.615
- Caracter semnat: având dimensiunea de 1 octet, are o gamă de modificări de la -128 la 127
- Unsigned Char: având dimensiunea de 1 octet, are o gamă de modificări de la 0 la 255.
Enumerare C++:
În limbajul de programare C++, „Enumeration” este un tip de date definit de utilizator. Enumerarea este declarată ca „ enumerare’ în C++. Este folosit pentru a aloca nume specifice oricărei constante utilizate în program. Îmbunătățește lizibilitatea și gradul de utilizare al programului.
Sintaxă:
Declarăm enumerarea în C++ după cum urmează:
enumerare enumerare_Nume { Constant1 , Constant2 , Constant3... }Avantajele enumerarii în C++:
Enum poate fi utilizat în următoarele moduri:
- Poate fi folosit frecvent în declarațiile switch case.
- Poate folosi constructori, câmpuri și metode.
- Poate extinde doar clasa „enum”, nu orice altă clasă.
- Poate crește timpul de compilare.
- Poate fi traversat.
Dezavantajele enumerarii în C++:
Enum are, de asemenea, câteva dezavantaje:
Dacă o dată este enumerat un nume, acesta nu poate fi folosit din nou în același domeniu.
De exemplu:
enumerare Zile{ sat , Soare , Ale mele } ;
int sat = 8 ; // Această linie are o eroare
Enum nu poate fi declarat înainte.
De exemplu:
enumerare forme ;culoarea clasei
{
gol a desena ( forme aShape ) ; //formele nu au fost declarate
} ;
Arată ca nume, dar sunt numere întregi. Deci, se pot converti automat în orice alt tip de date.
De exemplu:
enumerare forme{
Triunghi , cerc , pătrat
} ;
int culoare = albastru ;
culoare = pătrat ;
Exemplu:
În acest exemplu, vedem utilizarea enumerării C++:
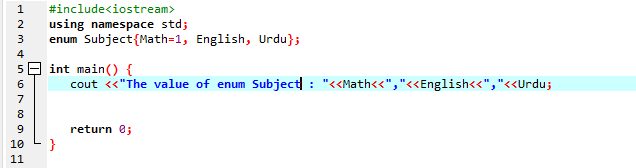
În această execuție a codului, în primul rând, începem cu #include
Iată rezultatul programului executat:

Deci, după cum puteți vedea, avem valori ale Subiectului: Matematică, Urdu, Engleză; adică 1,2,3.
Exemplu:
Iată un alt exemplu prin care ne clarificăm conceptele despre enumerare:
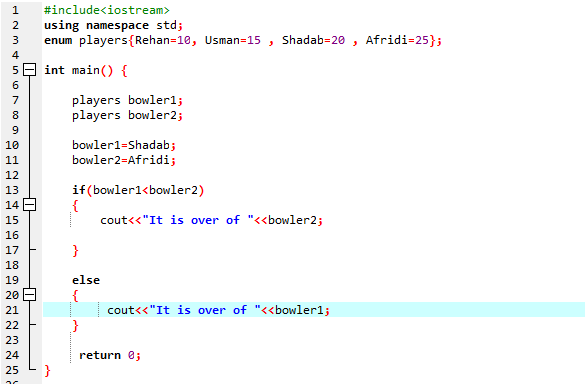
În acest program, începem prin a integra fișierul antet
Trebuie să folosim o declarație if-else . De asemenea, am folosit operatorul de comparație în interiorul declarației „dacă”, ceea ce înseamnă că comparăm dacă „bowler2” este mai mare decât „bowler1”. Apoi, blocul „dacă” se execută, ceea ce înseamnă că este terminarea lui Afridi. Apoi, am introdus „cout<<” pentru a afișa rezultatul. În primul rând, tipărim declarația „S-a terminat”. Apoi, valoarea lui „bowler2”. Dacă nu, blocul else este invocat, ceea ce înseamnă că este sfârșitul lui Shadab. Apoi, prin aplicarea comenzii „cout<<” afișăm declarația „S-a terminat”. Apoi, valoarea lui „bowler1”.

Conform declarației If-else, avem peste 25, care este valoarea lui Afridi. Înseamnă că valoarea variabilei enumerate „bowler2” este mai mare decât „bowler1”, de aceea este executată instrucțiunea „if”.
C++ Dacă altfel, comutați:
În limbajul de programare C++, folosim „instrucțiunea if” și „instrucțiunea de comutare” pentru a modifica fluxul programului. Aceste instrucțiuni sunt utilizate pentru a furniza mai multe seturi de comenzi pentru implementarea programului, în funcție de valoarea adevărată a instrucțiunilor menționate. În cele mai multe cazuri, folosim operatori ca alternative la declarația „dacă”. Toate aceste afirmații menționate mai sus sunt declarații de selecție care sunt cunoscute ca declarații decizionale sau condiționale.
Declarația „dacă”:
Această declarație este folosită pentru a testa o anumită condiție ori de câte ori doriți să schimbați fluxul oricărui program. Aici, dacă o condiție este adevărată, programul va executa instrucțiunile scrise, dar dacă condiția este falsă, se va termina. Să luăm în considerare un exemplu;
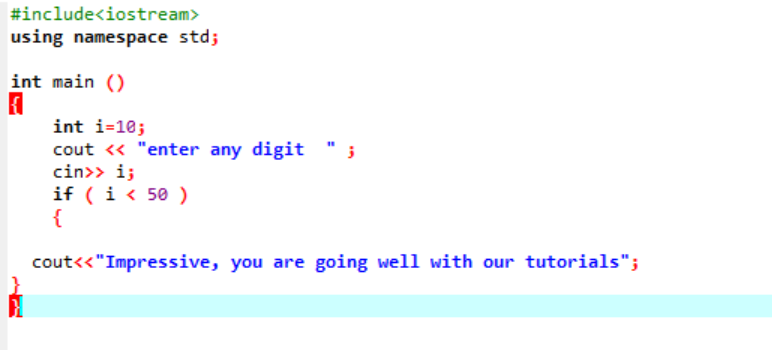
Aceasta este instrucțiunea simplă „dacă” folosită, în care inițializam o variabilă „int” ca 10. Apoi, o valoare este luată de la utilizator și este verificată încrucișată în instrucțiunea „dacă”. Dacă îndeplinește condițiile aplicate în instrucțiunea „dacă”, atunci rezultatul este afișat.

Deoarece cifra aleasă a fost 40, rezultatul este mesajul.
Declarația „Dacă altfel”:
Într-un program mai complex în care declarația „dacă” nu cooperează de obicei, folosim instrucțiunea „dacă-altfel”. În cazul dat, folosim declarația „if-else” pentru a verifica condițiile aplicate.
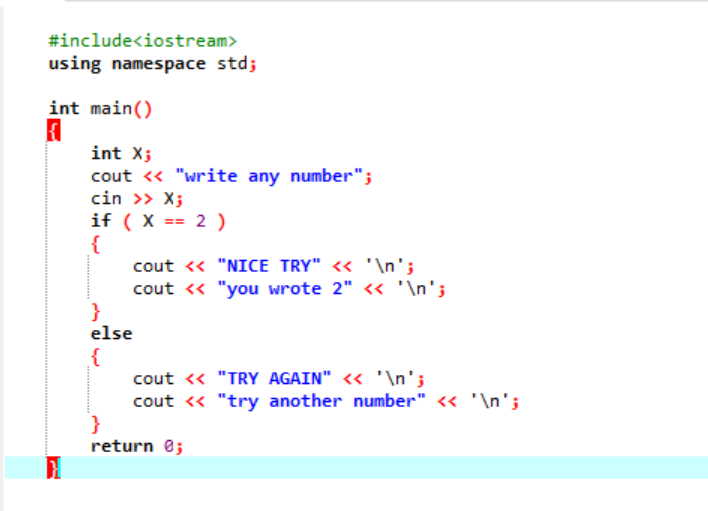
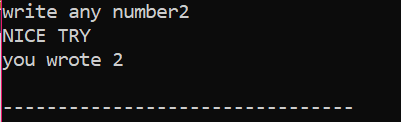
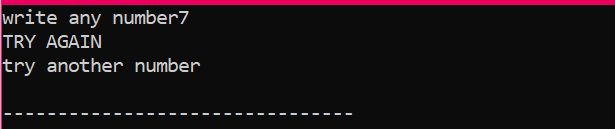
În primul rând, vom declara o variabilă de tip de date „int” numită „x” a cărei valoare este preluată de la utilizator. Acum, instrucțiunea „dacă” este utilizată în cazul în care am aplicat o condiție ca dacă valoarea întreagă introdusă de utilizator este 2. Ieșirea va fi cea dorită și va fi afișat un mesaj simplu „ÎNCERCAȚI FRUMOS”. În caz contrar, dacă numărul introdus nu este 2, rezultatul ar fi diferit.
Când utilizatorul scrie numărul 2, este afișată următoarea ieșire.
Când utilizatorul scrie orice alt număr cu excepția 2, rezultatul pe care îl obținem este:
Declarația If-else-if:
Instrucțiunile if-else-if imbricate sunt destul de complexe și sunt folosite atunci când există mai multe condiții aplicate în același cod. Să reflectăm la asta folosind un alt exemplu:
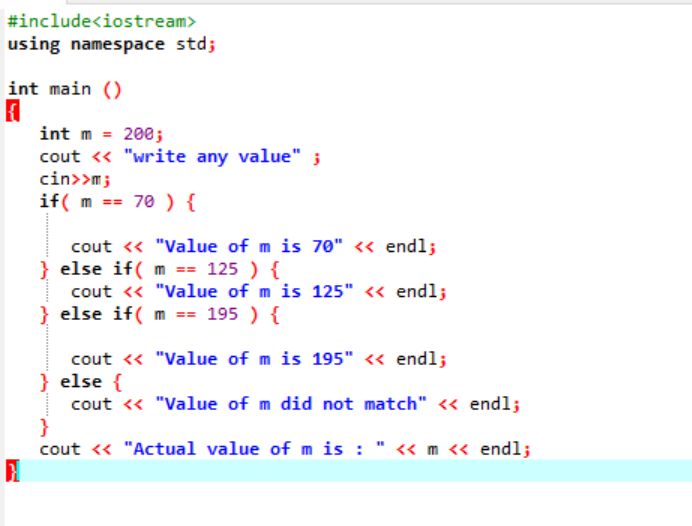
Aici, după integrarea fișierului antet și a spațiului de nume, am inițializat o valoare a variabilei „m” ca 200. Valoarea lui „m” este apoi luată de la utilizator și apoi verificată cu multiplele condiții menționate în program.
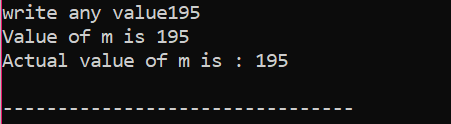
Aici, utilizatorul a ales valoarea 195. Acesta este motivul pentru care rezultatul arată că aceasta este valoarea reală a lui „m”.
Declarație Switch:
O instrucțiune „switch” este utilizată în C++ pentru o variabilă care trebuie testată dacă este egală cu o listă de valori multiple. În declarația „switch”, identificăm condițiile sub formă de cazuri distincte și toate cazurile au o pauză inclusă la sfârșitul fiecărei declarații de caz. Mai multe cazuri au condiții adecvate și instrucțiuni aplicate lor cu instrucțiuni break care termină instrucțiunea switch și trec la o instrucțiune implicită în cazul în care nu este acceptată nicio condiție.
Cuvânt cheie „pauză”:
Declarația switch conține cuvântul cheie „break”. Oprește executarea codului în cazul următor. Execuția instrucțiunii switch se termină atunci când compilatorul C++ dă peste cuvântul cheie „break” și controlul se mută la linia care urmează instrucțiunii switch. Nu este necesar să utilizați o declarație break într-un comutator. Execuția trece la următorul caz dacă nu este utilizat.
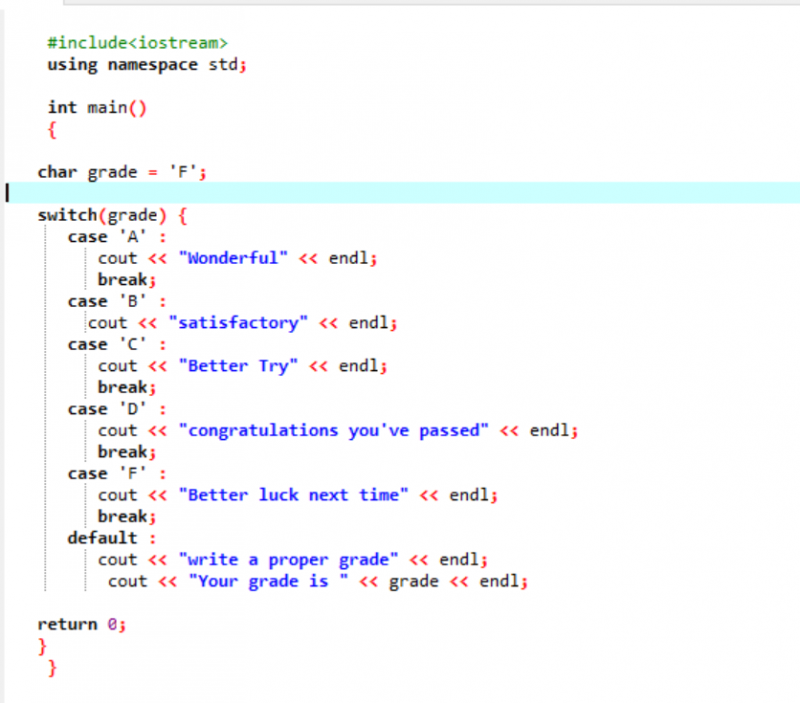
În prima linie a codului partajat, includem biblioteca. După care, adăugăm „namespace”. Invocăm principal() funcţie. Apoi, declarăm un tip de date caracter ca „F”. Această notă ar putea fi dorința dvs. și rezultatul ar fi afișat respectiv pentru cazurile alese. Am aplicat declarația switch pentru a obține rezultatul.
Dacă alegem „F” ca notă, rezultatul este „mai mult noroc data viitoare”, deoarece aceasta este afirmația că vrem să fie tipărită în cazul în care nota este „F”.

Să schimbăm nota în X și să vedem ce se întâmplă. Am scris „X” ca notă și rezultatul primit este afișat mai jos:

Deci, cazul necorespunzător din „comutator” mută automat indicatorul direct la instrucțiunea implicită și încheie programul.
Instrucțiunile if-else și switch au câteva caracteristici comune:
- Aceste instrucțiuni sunt utilizate pentru a gestiona modul în care este executat programul.
- Ambii evaluează o condiție și asta determină modul în care decurge programul.
- În ciuda faptului că au stiluri de reprezentare diferite, acestea pot fi folosite în același scop.
Declarațiile if-else și switch diferă în anumite moduri:
- În timp ce utilizatorul a definit valorile în instrucțiunile „switch case”, în timp ce constrângerile determină valorile în instrucțiunile „if-else”.
- Este nevoie de timp pentru a determina unde trebuie făcută schimbarea, este o provocare să modificați declarațiile „dacă altfel”. Pe de altă parte, declarațiile „switch” sunt ușor de actualizat, deoarece pot fi modificate cu ușurință.
- Pentru a include multe expresii, putem folosi numeroase afirmații „dacă altfel”.
Bucle C++:
Acum, vom descoperi cum să folosim bucle în programarea C++. Structura de control cunoscută sub numele de „buclă” repetă o serie de declarații. Cu alte cuvinte, se numește structură repetitivă. Toate instrucțiunile sunt executate simultan într-o structură secvențială . Pe de altă parte, în funcție de instrucțiunea specificată, structura condiției poate executa sau omite o expresie. Este posibil să fie necesară executarea unei instrucțiuni de mai multe ori în anumite situații.
Tipuri de buclă:
Există trei categorii de bucle:
Pentru buclă:
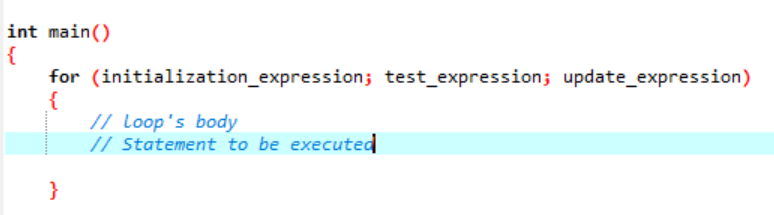
Bucla este ceva care se repetă ca un ciclu și se oprește atunci când nu validează condiția furnizată. O buclă „for” implementează o secvență de instrucțiuni de mai multe ori și condensează codul care face față variabilei buclei. Acest lucru demonstrează cum o buclă „for” este un tip specific de structură de control iterativă care ne permite să creăm o buclă care se repetă de un anumit număr de ori. Bucla ne-ar permite să executăm numărul „N” de pași folosind doar un cod dintr-o singură linie simplă. Să vorbim despre sintaxa pe care o vom folosi pentru ca o buclă „for” să fie executată în aplicația dumneavoastră software.
Sintaxa executării buclei „for”:
Exemplu:
Aici, folosim o variabilă de buclă pentru a regla această buclă într-o buclă „for”. Primul pas ar fi alocarea unei valori acestei variabile pe care o declarăm ca o buclă. După aceea, trebuie să definim dacă este mai mică sau mai mare decât valoarea contorului. Acum, corpul buclei urmează să fie executat și, de asemenea, variabila buclă este actualizată în cazul în care declarația returnează adevărată. Pașii de mai sus se repetă frecvent până ajungem la starea de ieșire.
- Expresie de inițializare: La început, trebuie să setăm contorul buclei la orice valoare inițială din această expresie.
- Testarea expresiei : Acum, trebuie să testăm condiția dată în expresia dată. Dacă criteriile sunt îndeplinite, vom efectua corpul buclei „for” și vom continua actualizarea expresiei; dacă nu, trebuie să ne oprim.
- Actualizare expresie: Această expresie mărește sau scade variabila buclă cu o anumită valoare după ce corpul buclei a fost executat.
Exemple de programe C++ pentru a valida o buclă „For”:
Exemplu:
Acest exemplu arată tipărirea valorilor întregi de la 0 la 10.
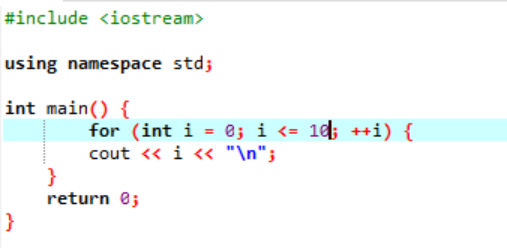
În acest scenariu, ar trebui să tipărim numerele întregi de la 0 la 10. Mai întâi, am inițializat o variabilă aleatoare i cu o valoare dată „0”, apoi parametrul de condiție pe care l-am folosit deja verifică condiția dacă i<=10. Și când îndeplinește condiția și devine adevărată, începe execuția buclei „for”. După execuție, dintre cei doi parametri de creștere sau decrementare, se va executa unul în care până când condiția specificată i<=10 se transformă în falsă, valoarea variabilei i se mărește.

Nr. de iterații cu condiția i<10:
| nr de iterații |
Variabile | i<10 | Acțiune |
| Primul | i=0 | Adevărat | 0 este afișat și i este incrementat cu 1. |
| Al doilea | i=1 | Adevărat | 1 este afișat și i este incrementat cu 2. |
| Al treilea | i=2 | Adevărat | 2 este afișat și i este incrementat cu 3. |
| Al patrulea | i=3 | Adevărat | 3 este afișat și i este incrementat cu 4. |
| a cincea | i=4 | Adevărat | 4 este afișat și i este incrementat cu 5. |
| Şaselea | i=5 | Adevărat | 5 este afișat și i este incrementat cu 6. |
| Al șaptelea | i=6 | Adevărat | 6 este afișat și i este incrementat cu 7. |
| Al optulea | i=7 | Adevărat | 7 este afișat și i este incrementat cu 8 |
| Nouălea | i=8 | Adevărat | 8 este afișat și i este incrementat cu 9. |
| Al zecelea | i=9 | Adevărat | 9 este afișat și i este incrementat cu 10. |
| Unsprezecelea | i=10 | Adevărat | 10 este afișat și i este incrementat cu 11. |
| Al doisprezecelea | i=11 | fals | Bucla este încheiată. |
Exemplu:
Următoarea instanță afișează valoarea numărului întreg:
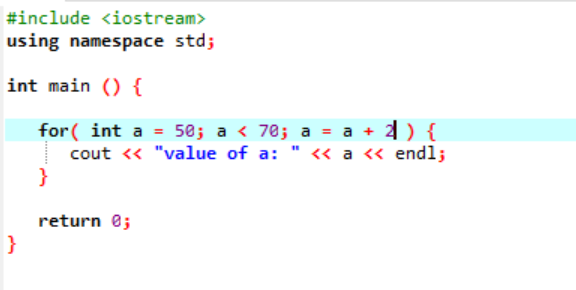
În cazul de mai sus, o variabilă numită „a” este inițializată cu o valoare dată 50. Se aplică o condiție în care variabila „a” este mai mică de 70. Apoi, valoarea lui „a” este actualizată astfel încât să fie adăugată cu 2. Valoarea lui „a” este apoi pornită de la o valoare inițială care a fost 50 și 2 este adăugat concomitent pe tot parcursul buclei până când condiția revine falsă și valoarea lui „a” crește de la 70 și bucla se termină.
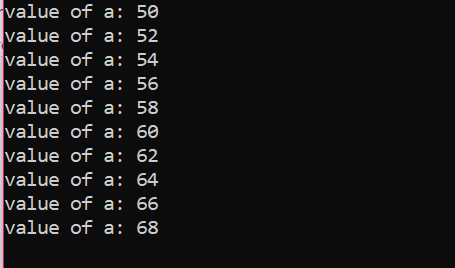
Număr de iterații:
| nr de Repetare |
Variabil | a=50 | Acțiune |
| Primul | a=50 | Adevărat | Valoarea lui a este actualizată prin adăugarea a încă două numere întregi, iar 50 devine 52 |
| Al doilea | a=52 | Adevărat | Valoarea lui a este actualizată prin adăugarea a încă două numere întregi și 52 devine 54 |
| Al treilea | a=54 | Adevărat | Valoarea lui a este actualizată prin adăugarea a încă două numere întregi, iar 54 devine 56 |
| Al patrulea | a=56 | Adevărat | Valoarea lui a este actualizată prin adăugarea a încă două numere întregi, iar 56 devine 58 |
| a cincea | a=58 | Adevărat | Valoarea lui a este actualizată prin adăugarea a încă două numere întregi și 58 devine 60 |
| Şaselea | a=60 | Adevărat | Valoarea lui a este actualizată prin adăugarea a încă două numere întregi, iar 60 devine 62 |
| Al șaptelea | a=62 | Adevărat | Valoarea lui a este actualizată prin adăugarea a încă două numere întregi, iar 62 devine 64 |
| Al optulea | a=64 | Adevărat | Valoarea lui a este actualizată prin adăugarea a încă două numere întregi, iar 64 devine 66 |
| Nouălea | a=66 | Adevărat | Valoarea lui a este actualizată prin adăugarea a încă două numere întregi, iar 66 devine 68 |
| Al zecelea | a=68 | Adevărat | Valoarea lui a este actualizată prin adăugarea a încă două numere întregi, iar 68 devine 70 |
| Unsprezecelea | a=70 | fals | Bucla este încheiată |
Buclă While:
Până când condiția definită este îndeplinită, pot fi executate una sau mai multe instrucțiuni. Când iterația este necunoscută în prealabil, este foarte utilă. Mai întâi, condiția este verificată și apoi intră în corpul buclei pentru a executa sau implementa instrucțiunea.
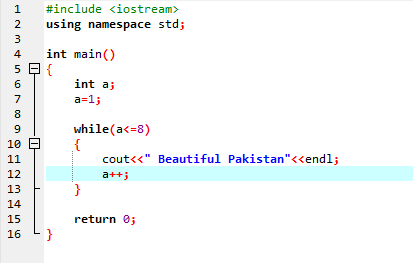
În prima linie, încorporăm fișierul antet
Buclă Do-While:
Când condiția definită este îndeplinită, sunt efectuate o serie de declarații. În primul rând, corpul buclei este efectuat. După aceea, condiția este verificată dacă este adevărată sau nu. Prin urmare, instrucțiunea este executată o dată. Corpul buclei este procesat într-o buclă „Do-while” înainte de a evalua condiția. Programul rulează ori de câte ori condiția necesară este îndeplinită. În caz contrar, când condiția este falsă, programul se încheie.
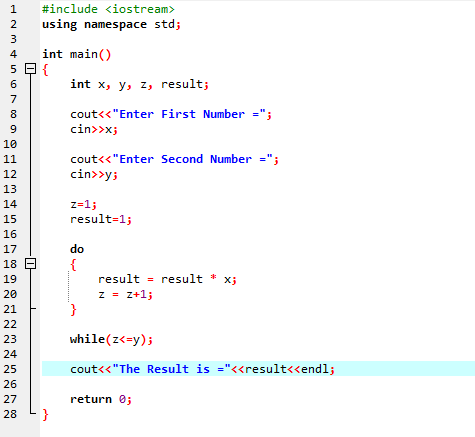
Aici, integrăm fișierul antet
C++ Continuare/Pare:
Declarație C++ Continue:
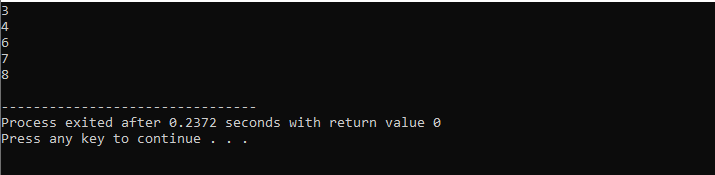
Instrucțiunea continue este folosită în limbajul de programare C++ pentru a evita o încarnare curentă a unei bucle, precum și pentru a muta controlul la iterația ulterioară. În timpul buclei, instrucțiunea continue poate fi folosită pentru a sări peste anumite instrucțiuni. Este, de asemenea, utilizat în buclă împreună cu declarațiile executive. Dacă condiția specifică este adevărată, toate instrucțiunile care urmează după instrucțiunea continue nu sunt implementate.
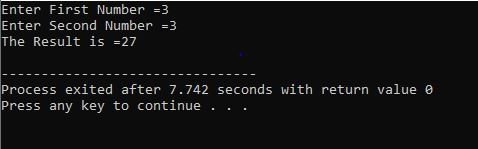
Cu bucla for:
În acest caz, folosim „bucla for” cu instrucțiunea continue din C++ pentru a obține rezultatul necesar în timp ce trecem unele cerințe specificate.

Începem prin a include biblioteca
Cu o buclă while:
Pe parcursul acestei demonstrații, am folosit atât instrucțiunea „while loop”, cât și instrucțiunea C++ „continue”, inclusiv unele condiții pentru a vedea ce fel de ieșire poate fi generată.
În acest exemplu, am stabilit o condiție pentru a adăuga numere doar la 40. Dacă numărul întreg introdus este un număr negativ, atunci bucla „while” se va termina. Pe de altă parte, dacă numărul este mai mare de 40, atunci acel număr specific va fi omis din iterație.
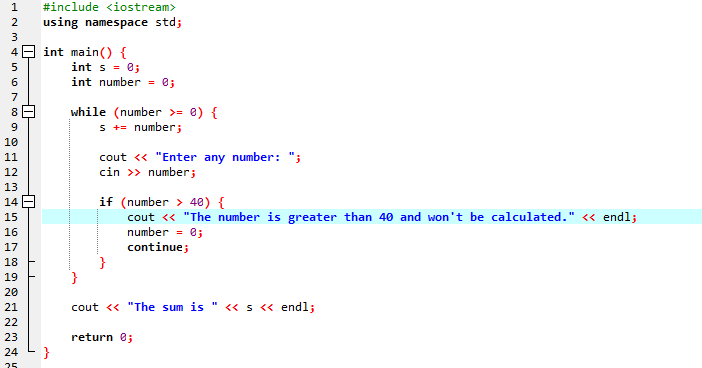
Vom include biblioteca
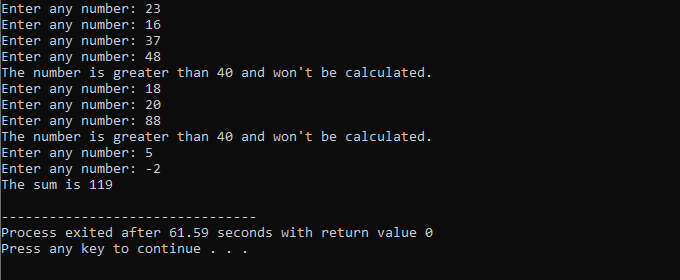
Declarație break C++:
Ori de câte ori instrucțiunea break este utilizată într-o buclă în C++, bucla se încheie instantaneu, precum și controlul programului repornește la instrucțiunea după buclă. De asemenea, este posibil să încheiați un caz în interiorul unei declarații „switch”.
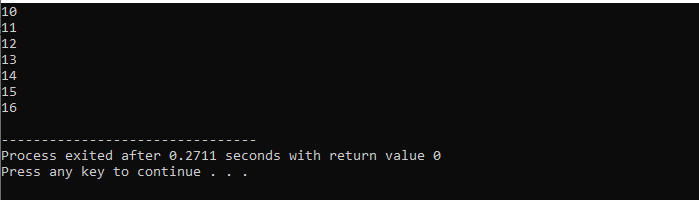
Cu bucla for:
Aici, vom folosi bucla „for” cu instrucțiunea „break” pentru a observa rezultatul iterând peste diferite valori.
În primul rând, încorporăm un fișier antet
Cu o buclă while:
Vom folosi bucla „while” împreună cu instrucțiunea break.
Începem prin a importa biblioteca
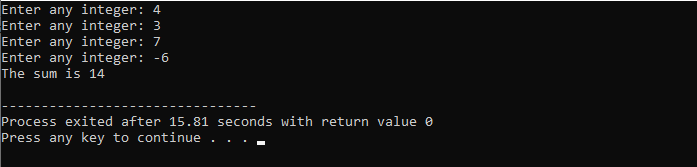
Funcții C++:
Funcțiile sunt folosite pentru a structura un program deja cunoscut în mai multe fragmente de coduri care se execută numai atunci când este apelat. În limbajul de programare C++, o funcție este definită ca un grup de instrucțiuni cărora le este dat un nume adecvat și numit de acestea. Utilizatorul poate trece date în funcțiile pe care le numim parametri. Funcțiile sunt responsabile pentru implementarea acțiunilor atunci când codul este cel mai probabil să fie reutilizat.
Crearea unei functii:
Deși C++ oferă multe funcții predefinite, cum ar fi principal(), care facilitează executarea codului. În același mod, vă puteți crea și defini funcțiile în funcție de cerințele dvs. La fel ca toate funcțiile obișnuite, aici, aveți nevoie de un nume pentru funcția dvs. pentru o declarație care este adăugată cu o paranteză după „()”.
Sintaxă:
Munca nulă ( ){
// corpul funcției
}
Void este tipul de returnare al funcției. Munca este numele dat, iar parantezele ar include corpul funcției în care adăugăm codul pentru execuție.
Apelarea unei funcții:
Funcțiile care sunt declarate în cod sunt executate numai atunci când sunt invocate. Pentru a apela o funcție, trebuie să specificați numele funcției împreună cu paranteza care este urmată de un punct și virgulă „;”.
Exemplu:
Să declarăm și să construim o funcție definită de utilizator în această situație.
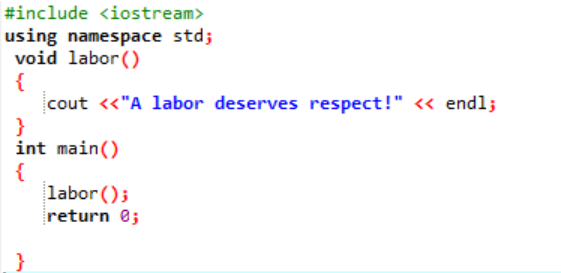
Inițial, așa cum este descris în fiecare program, ni se atribuie o bibliotecă și un spațiu de nume pentru a sprijini execuția programului. Funcția definită de utilizator muncă() este întotdeauna sunat înainte de a nota principal() funcţie. O funcție numită muncă() este declarat acolo unde este afișat mesajul „O muncă merită respect!”. În principal() funcția cu tipul de returnare întreg, numim muncă() funcţie.

Acesta este mesajul simplu care a fost definit în funcția definită de utilizator afișată aici cu ajutorul principal() funcţie.
Nulă:
În cazul menționat mai sus, am observat că tipul de returnare al funcției definite de utilizator este nul. Aceasta indică faptul că nicio valoare nu este returnată de funcție. Aceasta înseamnă că valoarea nu este prezentă sau este probabil nulă. Pentru că ori de câte ori o funcție imprimă doar mesajele, nu are nevoie de nicio valoare returnată.
Acest gol este utilizat în mod similar în spațiul de parametri al funcției pentru a afirma clar că această funcție nu ia nicio valoare reală în timp ce este apelată. În situația de mai sus, am numi și muncă() functioneaza ca:
Travaliu nul ( gol ){
Cout << „O muncă merită respect ! ” ;
}
Parametrii efectivi:
Se pot defini parametrii pentru funcție. Parametrii unei funcții sunt definiți în lista de argumente a funcției care se adaugă la numele funcției. Ori de câte ori apelăm funcția, trebuie să transmitem valorile autentice ale parametrilor pentru a finaliza execuția. Acestea sunt concluzionate ca parametrii reali. În timp ce parametrii care sunt definiți în timp ce funcția a fost definită sunt cunoscuți ca Parametri formali.
Exemplu:
În acest exemplu, suntem pe cale să schimbăm sau să înlocuim cele două valori întregi printr-o funcție.
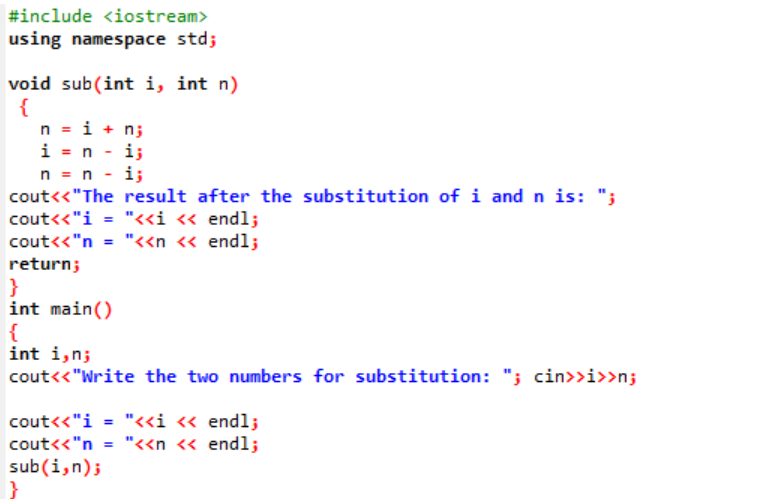
La început, luăm fișierul antet. Funcția definită de utilizator este numitul declarat și definit sub(). Această funcție este utilizată pentru înlocuirea celor două valori întregi care sunt i și n. În continuare, operatorii aritmetici sunt utilizați pentru schimbul acestor două numere întregi. Valoarea primului număr întreg „i” este stocată în locul valorii „n”, iar valoarea lui n este salvată în locul valorii lui „i”. Apoi, rezultatul după comutarea valorilor este imprimat. Dacă vorbim despre principal() funcție, luăm valorile celor două numere întregi de la utilizator și le afișăm. În ultimul pas, funcția definită de utilizator sub() este numit și cele două valori sunt schimbate.
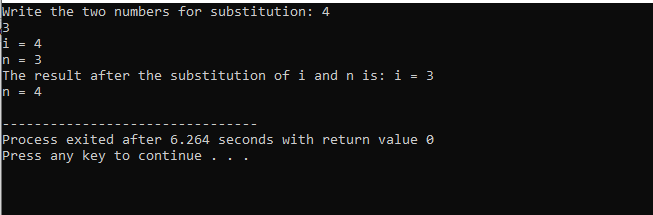
În acest caz de înlocuire a celor două numere, putem vedea clar că în timp ce folosim sub() funcția, valoarea lui „i” și „n” din lista de parametri sunt parametrii formali. Parametrii actuali sunt parametrul care trece la sfârșitul principal() funcția în care este apelată funcția de substituție.
Indicatori C++:
Pointer în C++ este destul de ușor de învățat și grozav de folosit. În limbajul C++, pointerii sunt folosiți pentru că ne ușurează munca și toate operațiunile funcționează cu mare eficiență atunci când sunt implicați pointeri. De asemenea, există câteva sarcini care nu vor fi îndeplinite decât dacă sunt folosiți pointerii, cum ar fi alocarea dinamică a memoriei. Vorbind despre pointeri, ideea principală, pe care trebuie să o înțelegem, este că pointerul este doar o variabilă care va stoca adresa exactă de memorie ca valoare. Utilizarea pe scară largă a pointerilor în C++ se datorează următoarelor motive:
- Pentru a trece o funcție la alta.
- Pentru a aloca noile obiecte pe heap.
- Pentru iterarea elementelor dintr-o matrice
De obicei, operatorul „&” (ampersand) este folosit pentru a accesa adresa oricărui obiect din memorie.
Indicatori și tipurile lor:
Pointerul are următoarele tipuri:
- Indicatori nul: Acestea sunt pointeri cu o valoare zero stocate în bibliotecile C++.
- Indicator aritmetic: Include patru operatori aritmetici majori care sunt accesibili, care sunt ++, –, +, -.
- O serie de indicatori: Sunt matrice care sunt folosite pentru a stoca niște pointeri.
- Pointer la pointer: Este locul în care un indicator este folosit peste un indicator.
Exemplu:
Gândiți-vă la exemplul următor în care sunt tipărite adresele câtorva variabile.
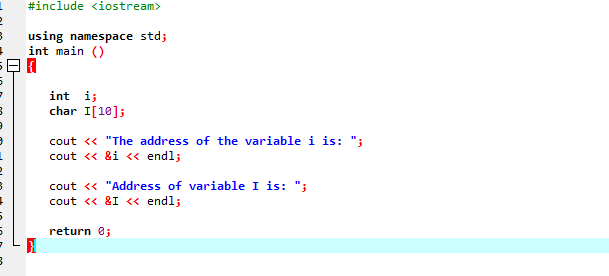
După ce includem fișierul antet și spațiul de nume standard, inițializam două variabile. Una este o valoare întreagă reprezentată de i’ și alta este o matrice de tip de caractere „I” cu dimensiunea de 10 caractere. Adresele ambelor variabile sunt apoi afișate folosind comanda „cout”.
Rezultatul pe care l-am primit este prezentat mai jos:
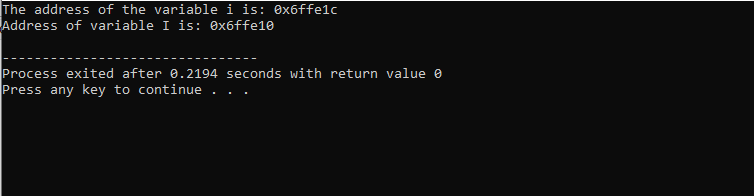
Acest rezultat arată adresa pentru ambele variabile.
Pe de altă parte, un pointer este considerat o variabilă a cărei valoare în sine este adresa unei variabile diferite. Un pointer indică întotdeauna un tip de date care are același tip care este creat cu un operator (*).
Declarația unui pointer:
Pointerul este declarat astfel:
tip * a fost - Nume ;Tipul de bază al indicatorului este indicat prin „tip”, în timp ce numele indicatorului este exprimat prin „var-name”. Și pentru a îndrepta o variabilă la indicatorul este folosit asterisc (*).
Modalități de atribuire a indicatoarelor la variabile:
Int * pi ; //pointerul unui tip de date întregDubla * pd ; //pointerul unui tip de date dublu
Pluti * pf ; //pointerul unui tip de date float
Char * pc ; //pointerul unui tip de date char
Aproape întotdeauna există un număr hexazecimal lung care reprezintă adresa de memorie care este inițial aceeași pentru toți pointerii, indiferent de tipurile lor de date.
Exemplu:
Următoarea instanță ar demonstra cum pointerii înlocuiesc operatorul „&” și stochează adresa variabilelor.
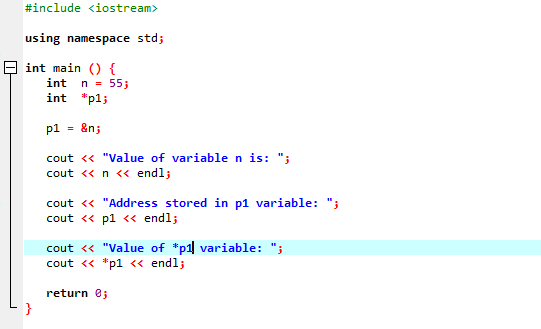
Vom integra suportul pentru biblioteci și directoare. Apoi, am invoca principal() funcție în care mai întâi declarăm și inițializam o variabilă „n” de tip „int” cu valoarea 55. În următoarea linie, inițializam o variabilă pointer numită „p1”. După aceasta, atribuim adresa variabilei „n” indicatorului „p1” și apoi arătăm valoarea variabilei „n”. Este afișată adresa lui „n” care este stocată în indicatorul „p1”. Ulterior, valoarea lui „*p1” este tipărită pe ecran utilizând comanda „cout”. Ieșirea este după cum urmează:
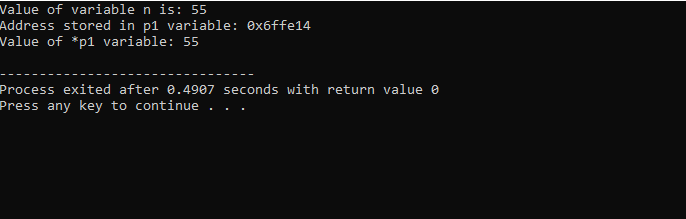
Aici, vedem că valoarea lui „n” este 55 și adresa lui „n” care a fost stocată în pointerul „p1” este afișată ca 0x6ffe14. Se găsește valoarea variabilei pointer și este 55, care este aceeași cu valoarea variabilei întregi. Prin urmare, un pointer stochează adresa variabilei și, de asemenea, indicatorul * are valoarea întregului stocat, care va returna, în consecință, valoarea variabilei stocată inițial.
Exemplu:
Să luăm în considerare un alt exemplu în care folosim un pointer care stochează adresa unui șir.
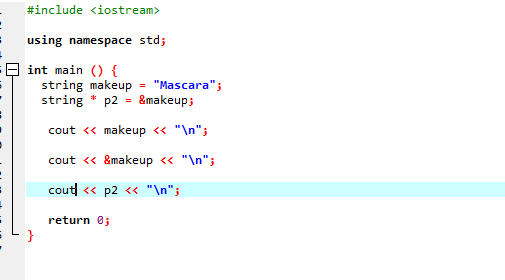
În acest cod, adăugăm mai întâi biblioteci și spațiu de nume. În principal() funcția trebuie să declarăm un șir numit „machiaj” care are valoarea „Mascara” în el. Un indicator de tip șir „*p2” este folosit pentru a stoca adresa variabilei de machiaj. Valoarea variabilei „machiaj” este apoi afișată pe ecran utilizând declarația „cout”. După aceasta, este tipărită adresa variabilei „makeup”, iar la final, este afișată variabila pointer „p2” arătând adresa de memorie a variabilei „makeup” cu indicatorul.
Ieșirea primită din codul de mai sus este după cum urmează:
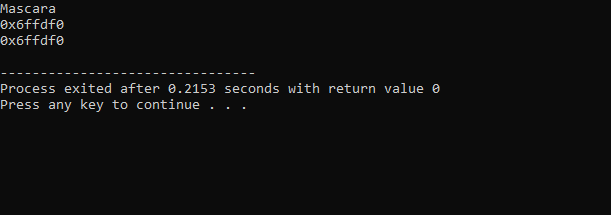
Prima linie are afișată valoarea variabilei „machiaj”. A doua linie arată adresa variabilei „machiaj”. În ultima linie, este afișată adresa de memorie a variabilei „machiaj” cu utilizarea pointerului.
Managementul memoriei C++:
Pentru gestionarea eficientă a memoriei în C++, multe operații sunt utile pentru gestionarea memoriei în timp ce lucrați în C++. Când folosim C++, cea mai frecvent utilizată procedură de alocare a memoriei este alocarea dinamică a memoriei în care memoriile sunt alocate variabilelor în timpul rulării; nu ca alte limbaje de programare în care compilatorul ar putea aloca memoria variabilelor. În C++ este necesară dealocarea variabilelor care au fost alocate dinamic, astfel încât memoria să fie eliberată liberă atunci când variabila nu mai este utilizată.
Pentru alocarea dinamică și dealocarea memoriei în C++, facem „ nou' și 'șterge' operațiuni. Este esențial să gestionați memoria astfel încât să nu se irosească memoria. Alocarea memoriei devine ușoară și eficientă. În orice program C++, memoria este folosită în unul dintre cele două aspecte: fie ca heap, fie ca stivă.
- Grămadă : Toate variabilele care sunt declarate în interiorul funcției și orice alt detaliu care este interconectat cu funcția sunt stocate în stivă.
- Morman : Orice fel de memorie neutilizată sau porțiunea din care alocam sau atribuim memoria dinamică în timpul execuției unui program este cunoscută sub numele de heap.
În timp ce folosim matrice, alocarea memoriei este o sarcină în care pur și simplu nu putem determina memoria decât dacă timpul de execuție. Deci, atribuim memorie maximă matricei, dar nici aceasta nu este o practică bună, deoarece în cele mai multe cazuri memoria rămâne nefolosită și este cumva irosită, ceea ce pur și simplu nu este o opțiune sau o practică bună pentru computerul dvs. personal. De aceea, avem câțiva operatori care sunt utilizați pentru a aloca memorie din heap în timpul rulării. Cei doi operatori majori „nou” și „ștergere” sunt utilizați pentru alocarea și dealocarea eficientă a memoriei.
operator nou C++:
Noul operator este responsabil pentru alocarea memoriei și este utilizat după cum urmează:
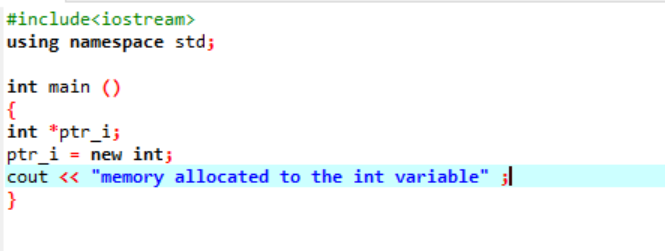
În acest cod, includem biblioteca

Memoria a fost alocată variabilei „int” cu succes prin utilizarea unui pointer.
operator de ștergere C++:
Ori de câte ori am terminat de folosit o variabilă, trebuie să dealocam memoria pe care i-am alocat-o cândva, deoarece nu mai este utilizată. Pentru aceasta, folosim operatorul „Ștergere” pentru a elibera memoria.
Exemplul pe care îl vom analiza chiar acum este includerea ambilor operatori.
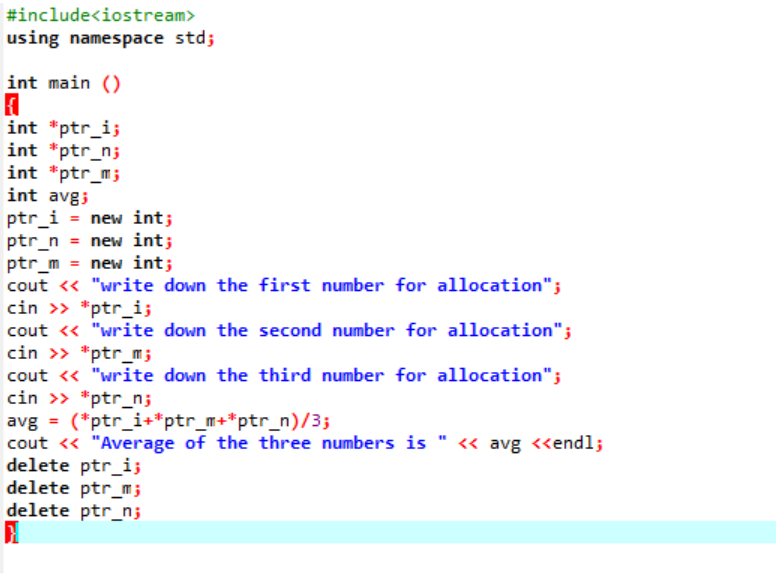
Calculăm media pentru trei valori diferite luate de la utilizator. Variabilele pointer sunt atribuite cu operatorul „nou” pentru a stoca valorile. Este implementată formula mediei. După aceasta, se utilizează operatorul „Ștergere” care șterge valorile care au fost stocate în variabilele pointerului folosind operatorul „nou”. Aceasta este alocarea dinamică în care alocarea se face în timpul rulării și apoi dealocarea are loc imediat după terminarea programului.
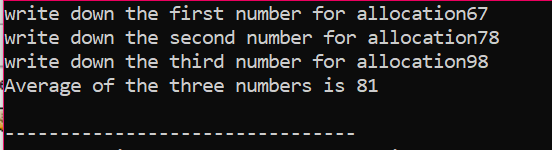
Utilizarea matricei pentru alocarea memoriei:
Acum, vom vedea cum sunt utilizați operatorii „nou” și „Ștergere” în timp ce se utilizează matrice. Alocarea dinamică se întâmplă în același mod ca și pentru variabile, deoarece sintaxa este aproape aceeași.
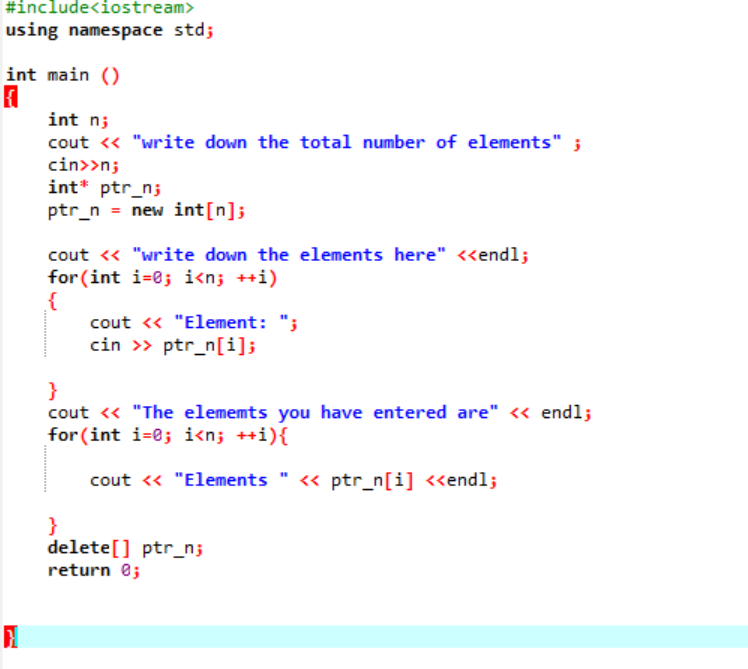
În cazul dat, luăm în considerare matricea de elemente a căror valoare este preluată de la utilizator. Elementele matricei sunt preluate și variabila pointer este declarată și apoi este alocată memoria. La scurt timp după alocarea memoriei, procedura de introducere a elementelor matricei este începută. Apoi, ieșirea pentru elementele matricei este afișată folosind o buclă „for”. Această buclă are condiția de iterație a elementelor având o dimensiune mai mică decât dimensiunea reală a matricei care este reprezentată de n.
Când toate elementele sunt utilizate și nu există nicio altă cerință ca acestea să fie folosite din nou, memoria alocată elementelor va fi dealocată folosind operatorul „șterge”.
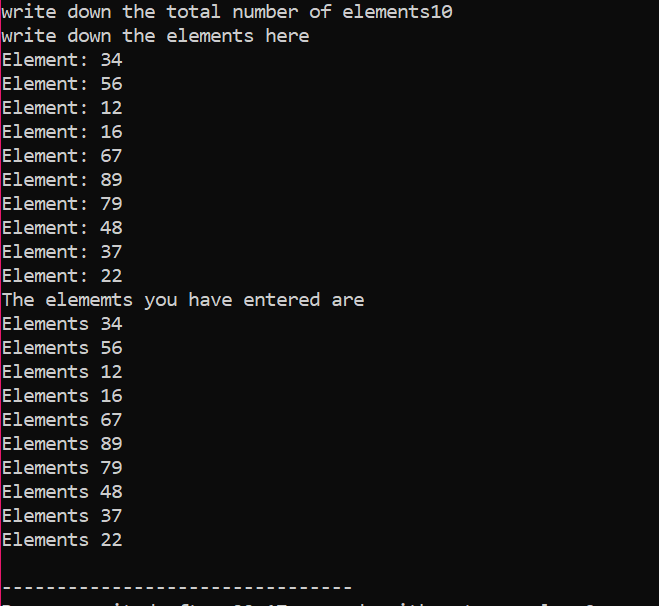
În rezultat, am putea vedea seturi de valori tipărite de două ori. Prima buclă „for” a fost folosită pentru scrierea valorilor pentru elemente, iar cealaltă buclă „for” este folosită pentru tipărirea valorilor deja scrise, arătând că utilizatorul a scris aceste valori pentru claritate.
Avantaje:
Operatorul „nou” și „Ștergerea” este întotdeauna prioritatea în limbajul de programare C++ și este utilizat pe scară largă. Atunci când aveți o discuție și înțelegere amănunțită, se observă că „noul” operator are prea multe avantaje. Avantajele „noului” operator pentru alocarea memoriei sunt următoarele:
- Noul operator poate fi supraîncărcat cu mai multă ușurință.
- În timp ce se alocă memorie în timpul execuției, ori de câte ori nu există suficientă memorie, ar exista o excepție automată, mai degrabă decât doar terminarea programului.
- Forța de utilizare a procedurii de tipare nu este prezentă aici, deoarece „noul” operator are exact același tip ca și memoria pe care i-am alocat-o.
- Operatorul „nou” respinge, de asemenea, ideea de a folosi operatorul sizeof() deoarece „nou” va calcula inevitabil dimensiunea obiectelor.
- Operatorul „nou” ne permite să inițializam și să declarăm obiectele chiar dacă generează spațiu pentru ele în mod spontan.
Matrice C++:
Vom avea o discuție amănunțită despre ce sunt tablourile și cum sunt declarate și implementate într-un program C++. Matricea este o structură de date utilizată pentru stocarea mai multor valori într-o singură variabilă, reducând astfel agitația de a declara mai multe variabile în mod independent.
Declarație de matrice:
Pentru a declara o matrice, trebuie mai întâi să definiți tipul de variabilă și să dați un nume adecvat matricei, care este apoi adăugat între paranteze drepte. Acesta va conține numărul de elemente care arată dimensiunea unui anumit tablou.
De exemplu:
Machiaj string [ 5 ] ;Această variabilă este declarată arătând că conține cinci șiruri de caractere într-o matrice numită „machiaj”. Pentru a identifica și a ilustra valorile pentru această matrice, trebuie să folosim parantezele, cu fiecare element separat separat prin virgule duble, fiecare separată cu o singură virgulă între ele.
De exemplu:
Machiaj string [ 5 ] = { 'Rimel' , 'Tentă' , 'Ruj' , 'Fundație' , 'Primul' } ;În mod similar, dacă doriți să creați o altă matrice cu un alt tip de date care ar trebui să fie „int”, atunci procedura ar fi aceeași, trebuie doar să schimbați tipul de date al variabilei, așa cum se arată mai jos:
int Multiplii [ 5 ] = { Două , 4 , 6 , 8 , 10 } ;În timp ce atribuiți valori întregi matricei, nu trebuie să le conțineți în virgule, ceea ce ar funcționa numai pentru variabila șir. Deci, în mod concludent, o matrice este o colecție de elemente de date interconectate cu tipuri de date derivate stocate în ele.
Cum accesează elementele din matrice?
Toate elementele incluse în matrice sunt atribuite cu un număr distinct care este numărul lor de index care este utilizat pentru accesarea unui element din matrice. Valoarea indexului începe cu 0 până la unul mai mic decât dimensiunea matricei. Prima valoare are valoarea indicelui 0.
Exemplu:
Luați în considerare un exemplu foarte simplu și simplu în care vom inițializa variabile într-o matrice.
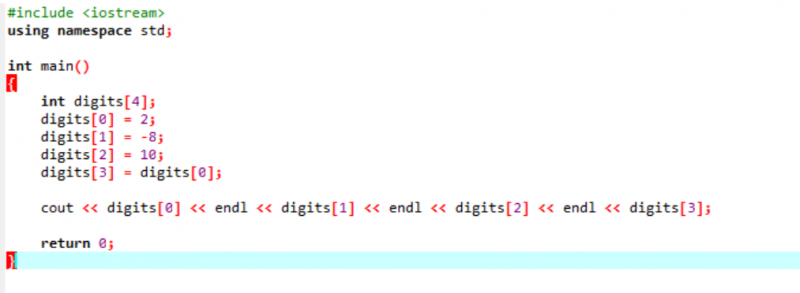
În primul pas, încorporăm fișierul antet
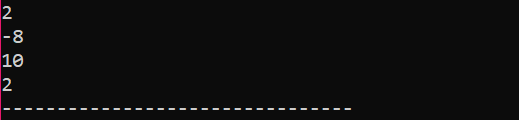
Acesta este rezultatul primit din codul de mai sus. Cuvântul cheie „endl” mută automat celălalt element pe linia următoare.
Exemplu:
În acest cod, folosim o buclă „for” pentru tipărirea elementelor unei matrice.

În exemplul de mai sus, adăugăm biblioteca esențială. Spațiul de nume standard este adăugat. The principal() funcția este funcția în care vom efectua toate funcționalitățile pentru execuția unui anumit program. În continuare, declarăm o matrice de tip int numită „Num”, care are o dimensiune de 10. Valoarea acestor zece variabile este preluată de la utilizator cu utilizarea buclei „for”. Pentru afișarea acestei matrice, este utilizată din nou o buclă „for”. Cele 10 numere întregi stocate în matrice sunt afișate cu ajutorul instrucțiunii „cout”.
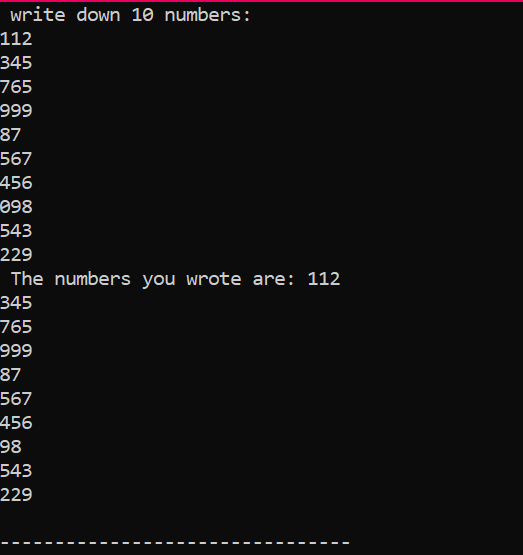
Aceasta este rezultatul pe care l-am obținut din execuția codului de mai sus, arătând 10 numere întregi având valori diferite.
Exemplu:
În acest scenariu, suntem pe cale să aflăm punctajul mediu al unui elev și procentul pe care l-a obținut la clasă.
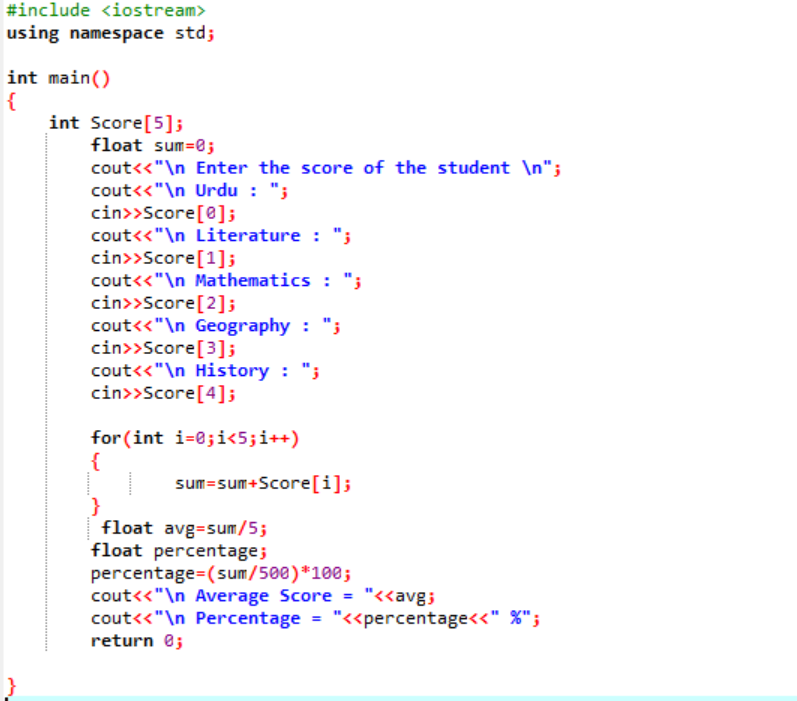
Mai întâi, trebuie să adăugați o bibliotecă care va oferi suport inițial pentru programul C++. În continuare, specificăm dimensiunea 5 a matricei numită „Scor”. Apoi, am inițializat o „sumă” variabilă a tipului de date float. Scorurile fiecărui subiect sunt preluate manual de la utilizator. Apoi, o buclă „for” este folosită pentru a afla media și procentul tuturor subiecților incluși. Suma este obținută prin utilizarea matricei și a buclei „for”. Apoi, media este găsită folosind formula mediei. După ce aflăm media, trecem valoarea acesteia la procentul care se adaugă formulei pentru a obține procentul. Media și procentul sunt apoi calculate și afișate.
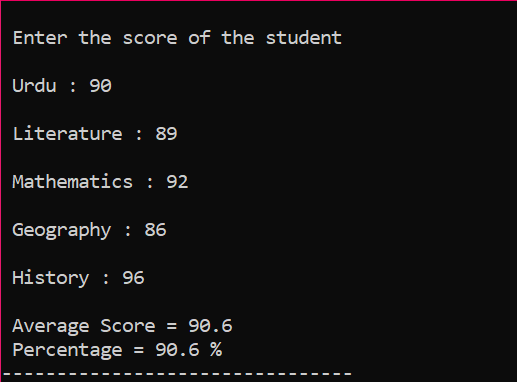
Acesta este rezultatul final în care sunt luate scorurile de la utilizator pentru fiecare subiect în mod individual și se calculează media și, respectiv, procentul.
Avantajele utilizării Arrays:
- Elementele din matrice sunt ușor de accesat datorită numărului de index care le este atribuit.
- Putem efectua cu ușurință operația de căutare pe o matrice.
- În cazul în care doriți complexități în programare, puteți utiliza o matrice bidimensională care caracterizează și matricele.
- Pentru a stoca mai multe valori care au un tip de date similar, o matrice ar putea fi utilizată cu ușurință.
Dezavantajele utilizării Arrays:
- Matricele au o dimensiune fixă.
- Matricele sunt omogene, ceea ce înseamnă că este stocat doar un singur tip de valoare.
- Matricele stochează datele în memoria fizică individual.
- Procesul de inserare și ștergere nu este ușor pentru matrice.
Obiecte și clase C++:
C++ este un limbaj de programare orientat pe obiecte, ceea ce înseamnă că obiectele joacă un rol vital în C++. Vorbind despre obiecte, trebuie mai întâi să ne gândim ce sunt obiectele, deci un obiect este orice instanță a clasei. Deoarece C++ se ocupă de conceptele OOP, lucrurile majore care trebuie discutate sunt obiectele și clasele. Clasele sunt de fapt tipuri de date care sunt definite de utilizator însuși și sunt desemnate să încapsuleze membrii datelor și funcțiile care sunt accesibile numai în care este creată instanța pentru o anumită clasă. Membrii datelor sunt variabilele care sunt definite în interiorul clasei.
Cu alte cuvinte, clasa este o schiță sau un design care este responsabil pentru definirea și declararea membrilor de date și a funcțiilor atribuite acelor membri de date. Fiecare dintre obiectele care sunt declarate în clasă ar putea împărtăși toate caracteristicile sau funcțiile demonstrate de clasă.
Să presupunem că există o clasă numită păsări, acum inițial toate păsările puteau zbura și avea aripi. Prin urmare, zborul este un comportament pe care îl adoptă aceste păsări, iar aripile fac parte din corpul lor sau o caracteristică de bază.
Definirea unei clase:
Pentru a defini o clasă, trebuie să urmăriți sintaxa și să o resetați în funcție de clasa dvs. Cuvântul cheie „clasă” este folosit pentru definirea clasei și toți ceilalți membri de date și funcții sunt definite în paranteze urmate de definiția clasei.
Class NameOfClass
{
Specificator de acces :
Membrii datelor ;
Funcții ale membrilor de date ( ) ;
} ;
Declararea obiectelor:
La scurt timp după definirea unei clase, trebuie să creăm obiectele pentru a accesa și defini funcțiile care au fost specificate de clasă. Pentru aceasta, trebuie să scriem numele clasei și apoi numele obiectului pentru declarare.
Accesarea membrilor datelor:
Funcțiile și membrii de date sunt accesați cu ajutorul unui operator simplu punct ‘.’. Membrii de date publice sunt, de asemenea, accesați cu acest operator, dar în cazul membrilor de date private, pur și simplu nu îi puteți accesa direct. Accesul membrilor datelor depinde de controalele de acces oferite de modificatorii de acces care sunt fie private, publice, fie protejate. Iată un scenariu care demonstrează cum se declară clasa simplă, membrii datelor și funcțiile.
Exemplu:
În acest exemplu, vom defini câteva funcții și vom accesa funcțiile clasei și membrii de date cu ajutorul obiectelor.
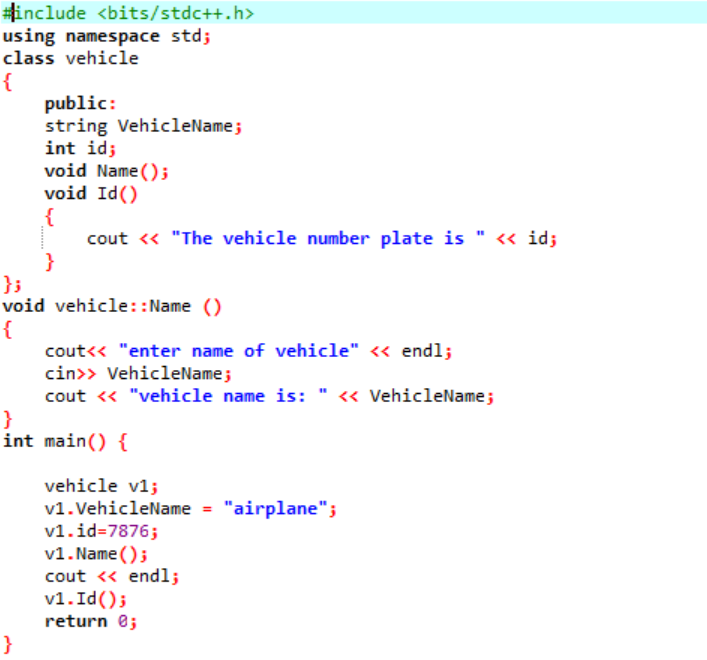
În primul pas, integrăm biblioteca după care trebuie să includem directoarele suport. Clasa este definită în mod explicit înainte de a apela principal() funcţie. Această clasă este denumită „vehicul”. Membrii datelor erau „numele vehiculului și „id-ul” acelui vehicul, care este numărul de plăcuță pentru vehiculul respectiv având un șir și, respectiv, tipul de date int. Cele două funcții sunt declarate pentru acești doi membri de date. The id() funcția afișează id-ul vehiculului. Deoarece membrii de date ai clasei sunt publice, le putem accesa și în afara clasei. Prin urmare, numim Nume() funcția în afara clasei și apoi luând valoarea pentru „VehicleName” de la utilizator și imprimând-o în pasul următor. În principal() funcția, declarăm un obiect al clasei necesare care va ajuta la accesarea membrilor de date și a funcțiilor din clasă. În plus, inițializam valorile pentru numele vehiculului și id-ul acestuia, numai dacă utilizatorul nu dă valoarea pentru numele vehiculului.
Aceasta este ieșirea primită atunci când utilizatorul dă numele vehiculului însuși, iar plăcuțele de înmatriculare sunt valoarea statică atribuită acestuia.
Vorbind despre definirea funcțiilor membre, trebuie să înțelegem că nu este întotdeauna obligatoriu să definiți funcția în interiorul clasei. După cum puteți vedea în exemplul de mai sus, definim funcția clasei în afara clasei deoarece membrii datelor sunt declarați public și acest lucru se face cu ajutorul operatorului de rezoluție a domeniului afișat ca „::” împreună cu numele lui. clasa și numele funcției.
Constructori și destructori C++:
Vom avea o viziune detaliată asupra acestui subiect cu ajutorul exemplelor. Ștergerea și crearea obiectelor în programarea C++ sunt foarte importante. Pentru asta, ori de câte ori creăm o instanță pentru o clasă, apelăm automat metodele constructorului în câteva cazuri.
Constructori:
După cum indică și numele, un constructor este derivat din cuvântul „construct” care specifică crearea a ceva. Deci, un constructor este definit ca o funcție derivată a clasei nou create care împarte numele clasei. Și este utilizat pentru inițializarea obiectelor incluse în clasă. De asemenea, un constructor nu are o valoare de returnare pentru el însuși, ceea ce înseamnă că nici tipul său de returnare nu va fi nici măcar nul. Nu este obligatoriu să acceptați argumentele, dar le puteți adăuga dacă este necesar. Constructorii sunt utili în alocarea memoriei obiectului unei clase și în stabilirea valorii inițiale pentru variabilele membre. Valoarea inițială ar putea fi transmisă sub formă de argumente funcției de constructor odată ce obiectul este inițializat.
Sintaxă:
NameOfTheClass ( ){
//corpul constructorului
}
Tipuri de constructori:
Constructor parametrizat:
După cum sa discutat mai devreme, un constructor nu are niciun parametru, dar se poate adăuga un parametru la alegere. Aceasta va inițializa valoarea obiectului în timp ce acesta este creat. Pentru a înțelege mai bine acest concept, luați în considerare următorul exemplu:
Exemplu:
În acest caz, vom crea un constructor al clasei și vom declara parametrii.
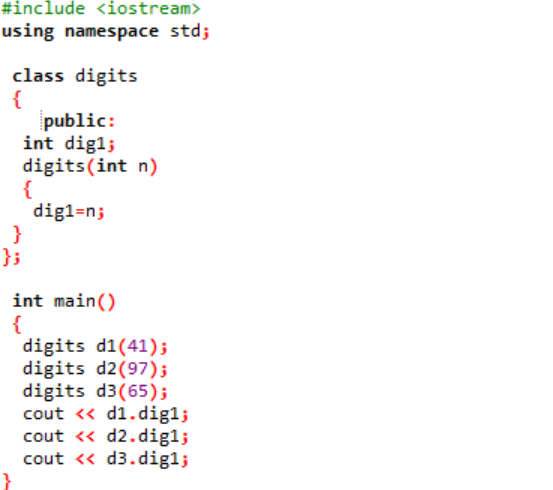
Includem fișierul antet chiar în primul pas. Următorul pas al utilizării unui spațiu de nume este susținerea directoarelor pentru program. O clasă numită „digits” este declarată unde mai întâi, variabilele sunt inițializate public, astfel încât să poată fi accesibile în tot programul. Este declarată o variabilă numită „dig1” cu tipul de date întreg. Apoi, am declarat un constructor al cărui nume este similar cu numele clasei. Acest constructor are o variabilă întreagă transmisă ca „n”, iar variabila de clasă „dig1” este setată egală cu n. În principal() functie a programului, trei obiecte pentru clasa „digits” sunt create si li se atribuie niste valori aleatorii. Aceste obiecte sunt apoi utilizate pentru a apela variabilele de clasă care sunt atribuite automat cu aceleași valori.
Valorile întregi sunt prezentate pe ecran ca ieșire.

Copiere constructor:
Este tipul de constructor care consideră obiectele drept argumente și dublează valorile membrilor de date ai unui obiect în celălalt. Prin urmare, acești constructori sunt utilizați pentru a declara și inițializa un obiect din celălalt. Acest proces se numește inițializare copie.
Exemplu:
În acest caz, constructorul de copiere va fi declarat.

În primul rând, integrăm biblioteca și directorul. Se declară o clasă numită „Nou” în care numerele întregi sunt inițializate ca „e” și „o”. Constructorul este făcut public acolo unde celor două variabile li se atribuie valorile și aceste variabile sunt declarate în clasă. Apoi, aceste valori sunt afișate cu ajutorul principal() funcția cu „int” ca tip de returnare. The afişa() funcția este apelată și definită ulterior, unde numerele sunt afișate pe ecran. În interiorul principal() funcția, obiectele sunt realizate și aceste obiecte alocate sunt inițializate cu valori aleatorii și apoi afişa() se foloseste metoda.
Ieșirea primită de utilizarea constructorului de copiere este dezvăluită mai jos.

Distrugători:
După cum definește numele, destructorii sunt folosiți pentru a distruge obiectele create de către constructor. Comparabil cu constructorii, destructorii au numele identic cu clasa, dar cu o tilde suplimentară (~) urmată.
Sintaxă:
~Nou ( ){
}
Destructorul nu primește niciun argument și nici măcar nu are nicio valoare de returnare. Compilatorul apelează implicit la ieșirea din program pentru stocarea de curățare care nu mai este accesibilă.
Exemplu:
În acest scenariu, folosim un destructor pentru ștergerea unui obiect.
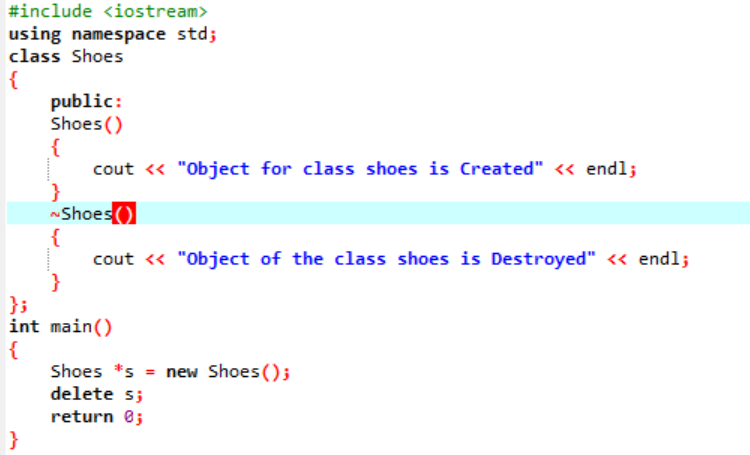
Aici se face o clasă de „Pantofi”. Este creat un constructor care are un nume similar cu cel al clasei. În constructor, este afișat un mesaj unde este creat obiectul. După constructor se face destructorul care șterge obiectele create cu constructorul. În principal() funcția, este creat un obiect indicator numit „s” și un cuvânt cheie „șterge” este utilizat pentru a șterge acest obiect.

Aceasta este rezultatul pe care l-am primit de la programul în care destructorul șterge și distruge obiectul creat.
Diferența dintre constructori și destructori:
| Constructorii | distrugătoare |
| Creează instanța clasei. | Distruge instanța clasei. |
| Are argumente de-a lungul numelui clasei. | Nu are argumente sau parametri |
| Apelat atunci când obiectul este creat. | Apelat atunci când obiectul este distrus. |
| Alocă memoria obiectelor. | Dealocarea memoriei obiectelor. |
| Poate fi supraîncărcat. | Nu poate fi supraîncărcat. |
Moștenirea C++:
Acum, vom afla despre moștenirea C++ și domeniul său de aplicare.
Moștenirea este metoda prin care o nouă clasă este generată sau descinde dintr-o clasă existentă. Clasa actuală este denumită „clasă de bază” sau, de asemenea, „clasă părinte”, iar noua clasă care este creată este denumită „clasă derivată”. Când spunem că o clasă copil este moștenită de la o clasă părinte înseamnă că copilul posedă toate proprietățile clasei părinte.
Moștenirea se referă la o relație (este o). Numim orice relație moștenire dacă „este-a” este folosit între două clase.
De exemplu:
- Un papagal este o pasăre.
- Un computer este o mașină.
Sintaxă:
În programarea C++, folosim sau scriem Moștenirea după cum urmează:
clasă < derivat - clasă >: < acces - specificatorul >< baza - clasă >Moduri de moștenire C++:
Moștenirea implică 3 moduri de a moșteni clase:
- Public: În acest mod, dacă o clasă copil este declarată, atunci membrii unei clase părinte sunt moșteniți de clasa copil ca aceiași într-o clasă părinte.
- Protejat: I În acest mod, membrii publici ai clasei părinte devin membri protejați în clasa copil.
- Privat : În acest mod, toți membrii unei clase părinte devin privați în clasa copil.
Tipuri de moștenire C++:
Următoarele sunt tipurile de moștenire C++:
1. Moștenire unică:
Cu acest tip de moștenire, clasele provin dintr-o clasă de bază.
Sintaxă:
clasa M{
Corp
} ;
clasa N : public M
{
Corp
} ;
2. Moștenire multiplă:
În acest tip de moștenire, o clasă poate descende din diferite clase de bază.
Sintaxă:
clasa M{
Corp
} ;
clasa N
{
Corp
} ;
clasa O : public M , public N
{
Corp
} ;
3. Moștenire pe mai multe niveluri:
O clasă copil este descendentă dintr-o altă clasă copil în această formă de moștenire.
Sintaxă:
clasa M{
Corp
} ;
clasa N : public M
{
Corp
} ;
clasa O : public N
{
Corp
} ;
4. Moștenirea ierarhică:
Mai multe subclase sunt create dintr-o clasă de bază în această metodă de moștenire.
Sintaxă:
clasa M{
Corp
} ;
clasa N : public M
{
Corp
} ;
clasa O : public M
{
} ;
5. Moștenire hibridă:
În acest tip de moștenire, moștenirile multiple sunt combinate.
Sintaxă:
clasa M{
Corp
} ;
clasa N : public M
{
Corp
} ;
clasa O
{
Corp
} ;
clasa P : public N , public O
{
Corp
} ;
Exemplu:
Vom rula codul pentru a demonstra conceptul de moștenire multiplă în programarea C++.
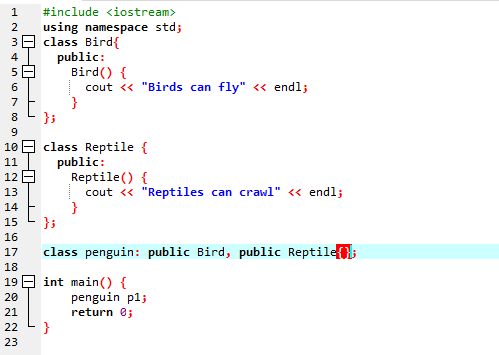
Deoarece am început cu o bibliotecă standard de intrare-ieșire, apoi am dat numele clasei de bază „Bird” și am făcut-o public, astfel încât membrii săi să poată fi accesibili. Apoi, avem clasa de bază „Reptile” și am făcut-o, de asemenea, publică. Apoi, avem „cout” pentru a tipări rezultatul. După aceasta, am creat un „pinguin” de clasă de copii. În principal() funcție am făcut obiectul clasei pinguin „p1”. În primul rând, se va executa clasa „Păsări”, apoi clasa „Reptile”.
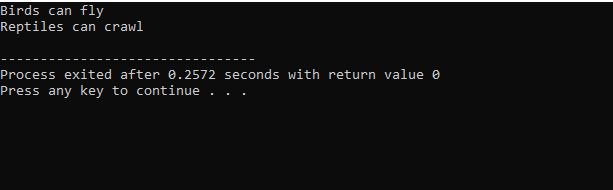
După executarea codului în C++, obținem instrucțiunile de ieșire ale claselor de bază „Bird” și „Reptile”. Înseamnă că o clasă „pinguin” este derivată din clasele de bază „Păsări” și „Reptile”, deoarece un pinguin este o pasăre, precum și o reptilă. Poate zbura, dar și să se târască. Prin urmare, moștenirile multiple au demonstrat că o clasă copil poate fi derivată din mai multe clase de bază.
Exemplu:
Aici vom executa un program pentru a arăta cum să utilizați Moștenirea pe mai multe niveluri.
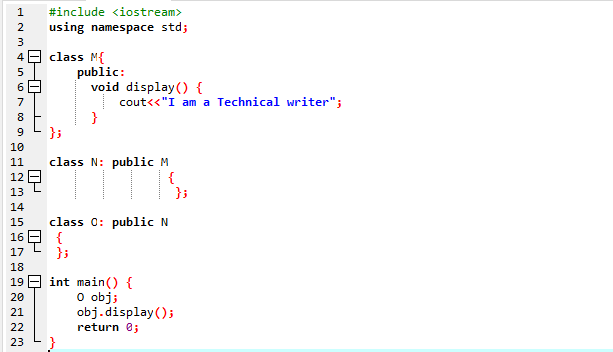
Am început programul nostru utilizând fluxuri de intrare-ieșire. Apoi, am declarat o clasă părinte „M” care este setată să fie publică. Am sunat la afişa() funcția și comanda „cout” pentru a afișa declarația. Apoi, am creat o clasă copil „N” care este derivată din clasa părinte „M”. Avem o nouă clasă copil „O” derivată din clasa copil „N”, iar corpul ambelor clase derivate este gol. În cele din urmă, invocăm principal() functie in care trebuie sa initializam obiectul clasei ‘O’. The afişa() funcția obiectului este utilizată pentru demonstrarea rezultatului.
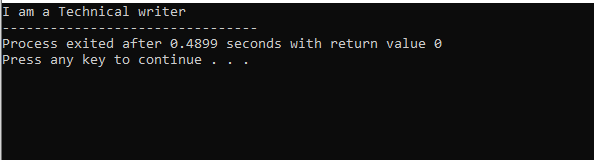
În această figură, avem rezultatul clasei „M”, care este clasa părinte, deoarece am avut a afişa() functioneaza in ea. Deci, clasa „N” este derivată din clasa părinte „M” și clasa „O” din clasa părinte „N”, care se referă la moștenirea pe mai multe niveluri.
Polimorfismul C++:
Termenul „polimorfism” reprezintă o colecție de două cuvinte „poli” și ' morfism’ . Cuvântul „Poly” reprezintă „multe”, iar „morfismul” reprezintă „forme”. Polimorfismul înseamnă că un obiect se poate comporta diferit în condiții diferite. Permite unui programator să refolosească și să extindă codul. Același cod acționează diferit în funcție de condiție. Activarea unui obiect poate fi folosită în timpul execuției.
Categorii de polimorfism:
Polimorfismul are loc în principal în două metode:
- Polimorfismul timpului de compilare
- Polimorfismul timpului de rulare
Să explicăm.
6. Polimorfismul timpului de compilare:
În acest timp, programul introdus este schimbat într-un program executabil. Înainte de implementarea codului, erorile sunt detectate. Există în primul rând două categorii.
- Supraîncărcarea funcției
- Supraîncărcarea operatorului
Să vedem cum folosim aceste două categorii.
7. Supraîncărcarea funcției:
Înseamnă că o funcție poate îndeplini diferite sarcini. Funcțiile sunt cunoscute ca supraîncărcate atunci când există mai multe funcții cu un nume similar, dar cu argumente distincte.
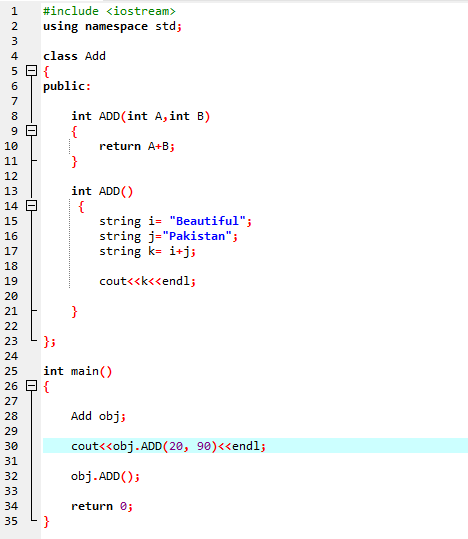
În primul rând, folosim biblioteca
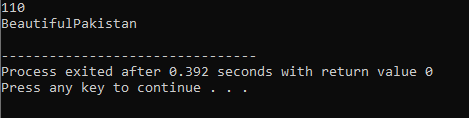
Supraîncărcarea operatorului:
Procesul de definire a mai multor funcționalități ale unui operator se numește supraîncărcare operator.
Exemplul de mai sus include fișierul antet
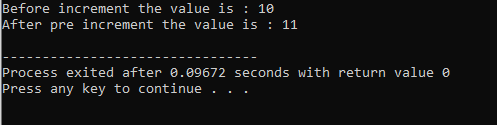
8. Polimorfismul timpului de rulare:
Este intervalul de timp în care rulează codul. După utilizarea codului, pot fi detectate erori.
Suprascrierea funcției:
Se întâmplă atunci când o clasă derivată folosește o definiție de funcție similară cu una dintre funcțiile membre ale clasei de bază.
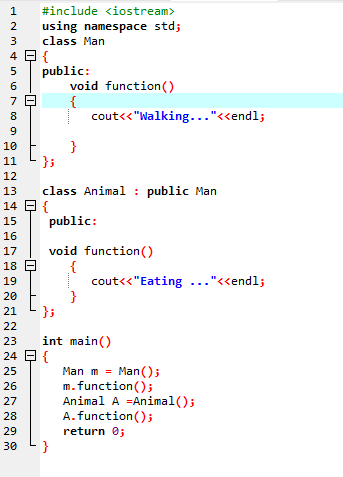
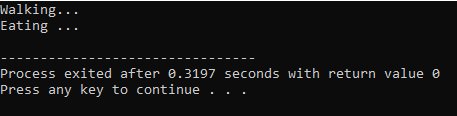
În prima linie, încorporăm biblioteca
Șiruri de caractere C++:
Acum, vom descoperi cum să declarăm și să inițializam șirul în C++. String-ul este utilizat pentru a stoca un grup de caractere în program. Stochează valori alfabetice, cifre și simboluri de tip special în program. A rezervat caractere ca o matrice în programul C++. Matricele sunt folosite pentru a rezerva o colecție sau o combinație de caractere în programarea C++. Un simbol special cunoscut sub numele de caracter nul este folosit pentru a termina matricea. Este reprezentată de secvența de escape (\0) și este folosită pentru a specifica sfârșitul șirului.
Obțineți șirul folosind comanda „cin”:
Este folosit pentru a introduce o variabilă șir fără spațiu liber în ea. În cazul dat, implementăm un program C++ care primește numele utilizatorului folosind comanda „cin”.
În primul pas, folosim biblioteca
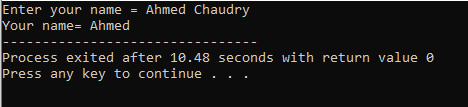
Utilizatorul introduce numele „Ahmed Chaudry”. Dar obținem doar „Ahmed” ca ieșire, mai degrabă decât „Ahmed Chaudry” complet, deoarece comanda „cin” nu poate stoca un șir cu spațiu liber. Stochează doar valoarea înainte de spațiu.
Obțineți șirul folosind funcția cin.get():
The obține() funcția comenzii cin este utilizată pentru a obține șirul de la tastatură care poate conține spații goale.
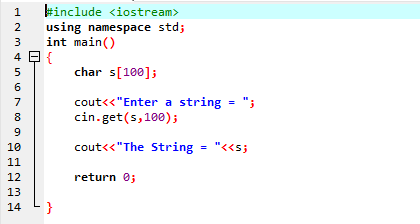
Exemplul de mai sus include biblioteca
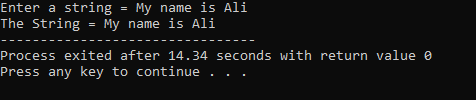
Un șir „Numele meu este Ali” este introdus de utilizator. Obținem șirul complet „Numele meu este Ali” ca rezultat, deoarece funcția cin.get() acceptă șirurile care conțin spații goale.
Folosind o matrice 2D (bidimensională) de șiruri:
În acest caz, luăm intrare (numele a trei orașe) de la utilizator utilizând o matrice 2D de șiruri.
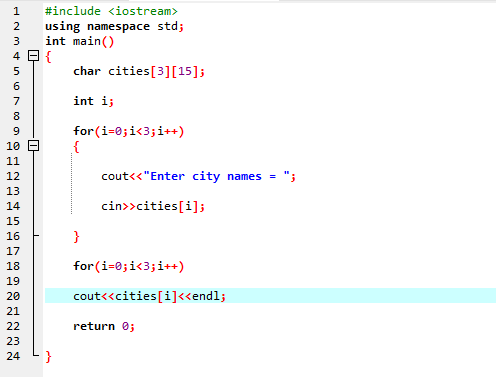
Mai întâi, integrăm fișierul antet
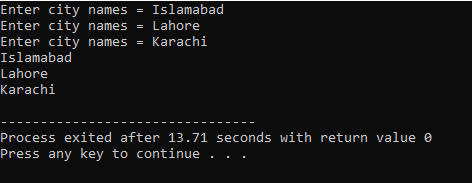
Aici, utilizatorul introduce numele a trei orașe diferite. Programul folosește un index de rând pentru a obține trei valori de șir. Fiecare valoare este reținută în propriul rând. Primul șir este stocat în primul rând și așa mai departe. Fiecare valoare de șir este afișată în același mod folosind indexul de rând.
Biblioteca standard C++:
Biblioteca C++ este un cluster sau o grupare de mai multe funcții, clase, constante și toate elementele aferente închise aproape într-un singur set adecvat, definind și declarând întotdeauna fișierele de antet standardizate. Implementarea acestora include două noi fișiere antet care nu sunt cerute de standardul C++ numite
Biblioteca standard elimină agitația de a rescrie instrucțiunile în timpul programării. Acesta are multe biblioteci în interior care au cod stocat pentru multe funcții. Pentru a folosi bine aceste biblioteci este obligatoriu să le legați cu ajutorul fișierelor de antet. Când importăm biblioteca de intrare sau de ieșire, aceasta înseamnă că importăm tot codul care a fost stocat în acea bibliotecă și așa putem folosi și funcțiile incluse în ea, ascunzând tot codul care s-ar putea să nu aveți nevoie vedea.
Biblioteca standard C++ acceptă următoarele două tipuri:
- O implementare găzduită care furnizează toate fișierele de antet esențiale ale bibliotecii standard descrise de standardul ISO C++.
- O implementare autonomă care necesită doar o parte din fișierele antet din biblioteca standard. Subsetul potrivit este:
| Atomic_signed_lock_free și atomic-unsigned_lock_free) |
|
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
| |
| |
| |
|
|
Câteva dintre fișierele de antet au fost deplorate de când au apărut ultimele 11 C++: acestea sunt
Diferențele dintre implementările găzduite și cele independente sunt ilustrate mai jos:
- În implementarea găzduită, trebuie să folosim o funcție globală care este funcția principală. În timp ce se află într-o implementare independentă, utilizatorul poate declara și defini funcțiile de pornire și de sfârșit pe cont propriu.
- O implementare de găzduire are un fir care rulează obligatoriu la momentul potrivirii. În timp ce, în implementarea independentă, implementatorii vor decide ei înșiși dacă au nevoie de suportul firului concurent în biblioteca lor.
Tipuri:
Atât cele independente, cât și cele găzduite sunt acceptate de C++. Fișierele antet sunt împărțite în următoarele două:
- piese Iostream
- Piese C++ STL (Biblioteca standard)
Ori de câte ori scriem un program pentru execuție în C++, apelăm întotdeauna funcțiile care sunt deja implementate în STL. Aceste funcții cunoscute preiau intrare și afișează ieșirile folosind operatori identificați cu eficiență.
Având în vedere istoria, STL a fost inițial numită Standard Template Library. Apoi, porțiunile bibliotecii STL au fost apoi standardizate în Biblioteca standard de C++ care este folosită în prezent. Acestea includ biblioteca de rulare ISO C++ și câteva fragmente din biblioteca Boost, inclusiv alte funcționalități importante. Ocazional STL denotă containerele sau mai frecvent algoritmii Bibliotecii standard C++. Acum, această bibliotecă STL sau standard de șabloane vorbește în întregime despre cunoscuta bibliotecă standard C++.
Spațiul de nume standard și fișierele antet:
Toate declarațiile de funcții sau variabile se fac în biblioteca standard cu ajutorul fișierelor de antet care sunt distribuite uniform între ele. Declarația nu s-ar întâmpla decât dacă nu includeți fișierele antet.
Să presupunem că cineva folosește liste și șiruri de caractere, trebuie să adauge următoarele fișiere de antet:
#include <șir>#include
Aceste paranteze unghiulare „<>” înseamnă că trebuie să căutați acest fișier de antet special în directorul care este definit și inclus. Se poate adăuga, de asemenea, o extensie „.h” la această bibliotecă, care se face dacă este necesar sau dorit. Dacă excludem biblioteca „.h”, avem nevoie de o adăugare „c” chiar înainte de începutul numelui fișierului, doar ca o indicație că acest fișier antet aparține unei biblioteci C. De exemplu, puteți scrie fie (#include
Vorbind despre spațiul de nume, întreaga bibliotecă standard C++ se află în interiorul acestui spațiu de nume notat ca std. Acesta este motivul pentru care denumirile standardizate de bibliotecă trebuie să fie definite în mod competent de către utilizatori. De exemplu:
Std :: cout << „Acesta va trece !/ n” ;Vectori C++:
Există multe moduri de stocare a datelor sau a valorilor în C++. Dar, deocamdată, căutăm cel mai simplu și mai flexibil mod de stocare a valorilor în timp ce scriem programele în limbajul C++. Deci, vectorii sunt containere care sunt secvențiate corespunzător într-un model de serie a cărui dimensiune variază în momentul execuției în funcție de inserarea și deducerea elementelor. Aceasta înseamnă că programatorul poate modifica dimensiunea vectorului în funcție de dorința sa în timpul execuției programului. Ele seamănă cu matricele în așa fel încât au și poziții de stocare comunicabile pentru elementele lor incluse. Pentru verificarea numărului de valori sau elemente prezente în interiorul vectorilor, trebuie să folosim un „ std::count’ funcţie. Vectorii sunt incluși în Biblioteca de șabloane standard din C++, așa că are un fișier de antet definit care trebuie inclus mai întâi, adică:
#includeDeclaraţie:
Declarația unui vector este prezentată mai jos.
Std :: vector < DT > NameOfVector ;Aici, vectorul este cuvântul cheie folosit, DT-ul arată tipul de date al vectorului care poate fi înlocuit cu int, float, char sau orice alte tipuri de date asociate. Declarația de mai sus poate fi rescrisă astfel:
Vector < pluti > Procent ;Dimensiunea pentru vector nu este specificată deoarece dimensiunea poate crește sau scădea în timpul execuției.
Inițializarea vectorilor:
Pentru inițializarea vectorilor, există mai multe moduri în C++.
Tehnica numarul 1:
Vector < int > v1 = { 71 , 98 , 3. 4 , 65 } ;Vector < int > v2 = { 71 , 98 , 3. 4 , 65 } ;
În această procedură, atribuim direct valorile pentru ambii vectori. Valorile atribuite ambelor sunt exact similare.
Tehnica numarul 2:
Vector < int > v3 ( 3 , cincisprezece ) ;În acest proces de inițializare, 3 dictează dimensiunea vectorului și 15 este datele sau valoarea care a fost stocată în el. Este creat un vector de tipul de date „int” cu dimensiunea dată de 3 care stochează valoarea 15, ceea ce înseamnă că vectorul „v3” stochează următoarele:
Vector < int > v3 = { cincisprezece , cincisprezece , cincisprezece } ;Operațiuni majore:
Operațiile majore pe care le vom implementa pe vectorii din clasa de vectori sunt:
- Adăugarea unei valori
- Accesarea unei valori
- Modificarea unei valori
- Ștergerea unei valori
Adăugarea și ștergerea:
Adunarea și ștergerea elementelor din interiorul vectorului se fac sistematic. În cele mai multe cazuri, elementele sunt introduse la finisarea containerelor vectoriale, dar puteți adăuga și valori în locul dorit, care vor muta în cele din urmă celelalte elemente în noile lor locații. În timp ce, la ștergere, când valorile sunt șterse din ultima poziție, se va reduce automat dimensiunea containerului. Dar atunci când valorile din interiorul containerului sunt șterse aleatoriu dintr-o anumită locație, noile locații sunt atribuite automat celorlalte valori.
Functii folosite:
Pentru a modifica sau modifica valorile stocate în interiorul vectorului, există câteva funcții predefinite cunoscute sub numele de modificatori. Acestea sunt după cum urmează:
- Insert(): este folosit pentru adăugarea unei valori în interiorul unui container vectorial într-o anumită locație.
- Erase(): este folosit pentru eliminarea sau ștergerea unei valori în interiorul unui container vector într-o anumită locație.
- Swap(): este folosit pentru schimbul de valori în interiorul unui container vectorial care aparține aceluiași tip de date.
- Assign(): Este folosit pentru alocarea unei noi valori valorii stocate anterior în interiorul containerului vectorial.
- Begin(): este folosit pentru returnarea unui iterator în interiorul unei bucle care se adresează primei valori a vectorului din interiorul primului element.
- Clear(): este folosit pentru ștergerea tuturor valorilor stocate în interiorul unui container vectorial.
- Push_back(): Este folosit pentru adăugarea unei valori la finisarea containerului vector.
- Pop_back(): Este folosit pentru ștergerea unei valori la finisarea containerului vector.
Exemplu:
În acest exemplu, modificatorii sunt utilizați de-a lungul vectorilor.
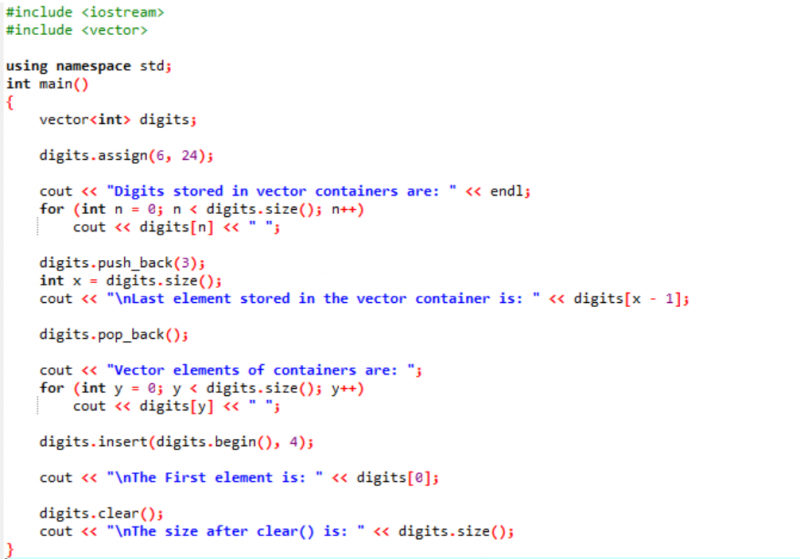
În primul rând, includem fișierele antet
Ieșirea este afișată mai jos.

Fișiere C++ Intrare Ieșire:
Un fișier este un ansamblu de date interconectate. În C++, un fișier este o secvență de octeți care sunt colectați împreună în ordine cronologică. Majoritatea fișierelor există în interiorul discului. Dar, de asemenea, dispozitivele hardware precum benzi magnetice, imprimante și linii de comunicație sunt, de asemenea, incluse în fișiere.
Intrarea și ieșirea în fișiere sunt caracterizate de trei clase principale:
- Clasa „istream” este utilizată pentru preluarea datelor.
- Clasa „ostream” este folosită pentru afișarea rezultatelor.
- Pentru intrare și ieșire, utilizați clasa „iostream”.
Fișierele sunt gestionate ca fluxuri în C++. Când luăm intrare și ieșire într-un fișier sau dintr-un fișier, următoarele sunt clasele care sunt utilizate:
- Offstream: Este o clasă de flux care este folosită pentru scrierea într-un fișier.
- Ifstream: Este o clasă de flux care este utilizată pentru a citi conținutul dintr-un fișier.
- Curent: Este o clasă de flux care este folosită atât pentru citire, cât și pentru scriere într-un fișier sau dintr-un fișier.
Clasele „istream” și „ostream” sunt strămoșii tuturor claselor menționate mai sus. Fluxurile de fișiere sunt la fel de ușor de utilizat ca și comenzile „cin” și „cout”, cu doar diferența de a asocia aceste fluxuri de fișiere cu alte fișiere. Să vedem un exemplu de studiat pe scurt despre clasa „fstream”:
Exemplu:
În acest caz, scriem date într-un fișier.
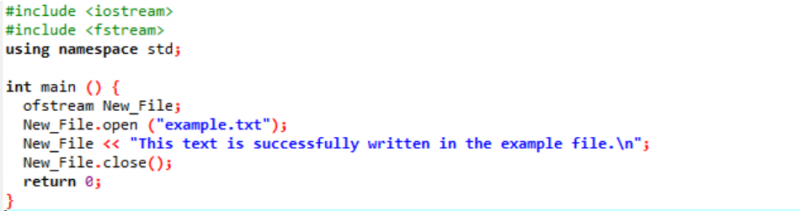
În primul pas, integrăm fluxul de intrare și ieșire. Fișierul antet

„Exemplu” fișierul este deschis de pe computerul personal, iar textul scris pe fișier este imprimat pe acest fișier text, așa cum se arată mai sus.
Deschiderea unui fișier:
Când un fișier este deschis, acesta este reprezentat de un flux. Este creat un obiect pentru fișier, așa cum a fost creat New_File în exemplul anterior. Toate operațiunile de intrare și de ieșire care au fost efectuate pe flux sunt aplicate automat fișierului în sine. Pentru deschiderea unui fișier, funcția open() este utilizată ca:
Deschis ( NameOfFile , modul ) ;Aici, modul este neobligatoriu.
Închiderea unui fișier:
Odată ce toate operațiunile de intrare și ieșire sunt terminate, trebuie să închidem fișierul care a fost deschis pentru editare. Ni se cere să angajăm un închide() functioneaza in aceasta situatie.
Fișier_nou. închide ( ) ;Când se face acest lucru, fișierul devine indisponibil. Dacă în orice circumstanțe obiectul este distrus, chiar fiind legat de fișier, destructorul va apela spontan funcția close().
Fișiere text:
Fișierele text sunt folosite pentru a stoca textul. Prin urmare, dacă textul este fie introdus, fie afișat, acesta va avea unele modificări de formatare. Operația de scriere în interiorul fișierului text este aceeași cu cea cu care executăm comanda „cout”.
Exemplu:
În acest scenariu, scriem date în fișierul text care a fost deja realizat în ilustrația anterioară.
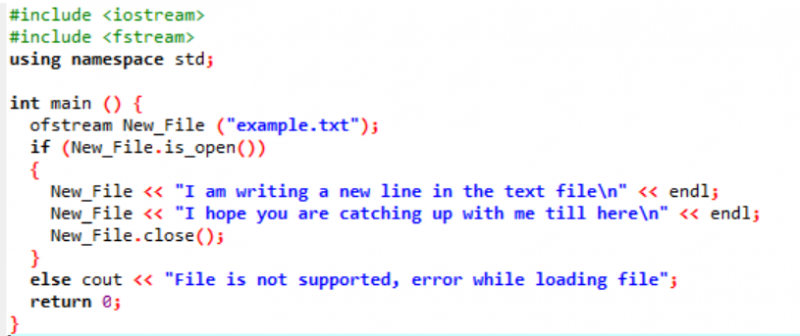
Aici scriem date în fișierul numit „exemplu” folosind funcția New_File(). Deschidem fișierul „exemplu” utilizând fișierul deschis() metodă. „Ofstream” este folosit pentru a adăuga date în fișier. După ce ați făcut toată munca din interiorul fișierului, fișierul necesar este închis prin utilizarea fișierului închide() funcţie. Dacă fișierul nu deschide, se afișează mesajul de eroare „Fișierul nu este acceptat, eroare la încărcarea fișierului”.

Fișierul se deschide și textul este afișat pe consolă.
Citirea unui fișier text:
Citirea unui fișier este afișată cu ajutorul exemplului următor.
Exemplu:
„ifstream” este utilizat pentru citirea datelor stocate în fișier.
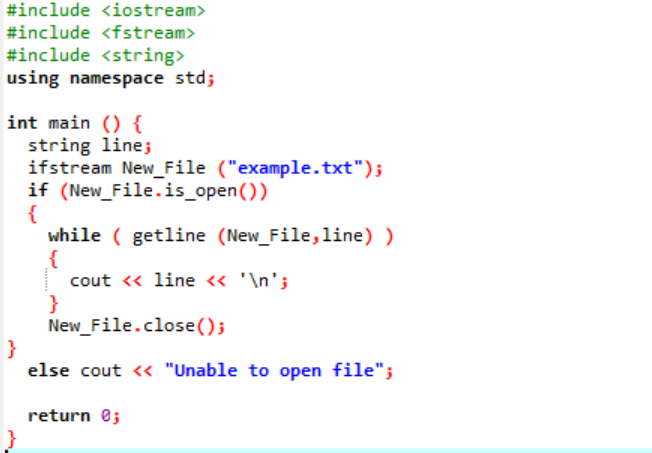
Exemplul include fișierele de antet majore
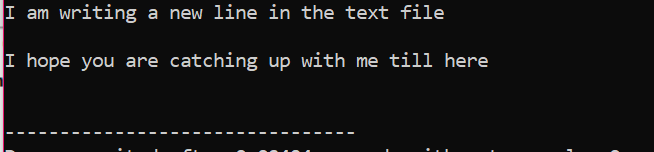
Toate informațiile stocate în fișierul text sunt afișate pe ecran așa cum se arată.
Concluzie
În ghidul de mai sus, am aflat despre limbajul C++ în detaliu. Alături de exemple, fiecare subiect este demonstrat și explicat, iar fiecare acțiune este elaborată.