Panda umple valorile NaN
Dacă o coloană din cadrul de date are valori NaN sau None, puteți folosi funcțiile „fillna()” sau „replace()” pentru a le completa cu zero (0).
completati()
Valorile NA/NaN sunt completate cu abordarea furnizată folosind funcția „fillna()”. Poate fi utilizat luând în considerare următoarea sintaxă:
Dacă doriți să completați valorile NaN pentru o singură coloană, sintaxa este următoarea:

Când vi se cere să completați valorile NaN pentru întregul DataFrame, sintaxa este așa cum este furnizată:

A inlocui()
Pentru a înlocui o singură coloană de valori NaN, sintaxa furnizată este următoarea:

Întrucât, pentru a înlocui valorile NaN ale întregului DataFrame, trebuie să folosim următoarea sintaxă menționată:

În acest articol, acum vom explora și vom învăța implementarea practică a ambelor metode pentru a completa valorile NaN în Pandas DataFrame.
Exemplul 1: Completați valorile NaN utilizând metoda Pandas „Fillna()”.
Această ilustrație demonstrează aplicarea funcției Pandas „DataFrame.fillna()” pentru a completa cu 0 valorile NaN din DataFrame-ul dat. Puteți fie completa valorile lipsă într-o singură coloană, fie le puteți completa pentru întregul DataFrame. Aici, vom vedea ambele aceste tehnici.
Pentru a pune în practică aceste strategii, trebuie să obținem o platformă adecvată pentru execuția programului. Deci, am decis să folosim instrumentul „Spyder”. Am început codul nostru Python importând setul de instrumente „pandas” în program, deoarece trebuie să folosim caracteristica Pandas pentru a construi DataFrame, precum și pentru a completa valorile lipsă din acel DataFrame. „pd” este folosit ca alias de „pandas” în tot programul.
Acum, avem acces la funcțiile Pandas. Mai întâi folosim funcția „pd.DataFrame()” pentru a ne genera DataFrame. Am invocat această metodă și am inițializat-o cu trei coloane. Titlurile acestor coloane sunt „M1”, „M2” și „M3”. Valorile din coloana „M1” sunt „1”, „Niciuna”, „5”, „9” și „3”. Intrările din „M2” sunt „Niciuna”, „3”, „8”, „4” și „6”. În timp ce „M3” stochează datele ca „1”, „2”, „3”, „5” și „Niciuna”. Avem nevoie de un obiect DataFrame în care să putem stoca acest DataFrame atunci când este apelată metoda „pd.DataFrame()”. Am creat un obiect DataFrame „lipsă” și l-am atribuit după rezultatul pe care l-am obținut din funcția „pd.DataFrame()”. Apoi, am folosit metoda „print()” a lui Python pentru a afișa DataFrame pe consola Python.
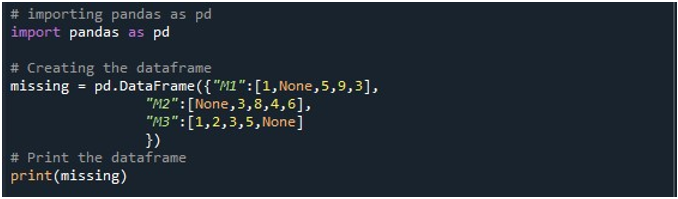
Când rulăm această bucată de cod, un DataFrame cu trei coloane poate fi vizualizat pe terminal. Aici, putem observa că toate cele trei coloane conțin valorile nule în ele.
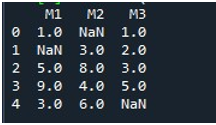
Am creat un DataFrame cu niște valori nule pentru a aplica funcția Pandas „fillna()” pentru a completa valorile lipsă cu 0. Să învățăm cum putem face asta.
După afișarea DataFrame-ului, am invocat funcția Pandas „fillna()”. Aici, vom învăța să completăm valorile lipsă într-o singură coloană. Sintaxa pentru aceasta este deja menționată la începutul tutorialului. Am furnizat numele DataFrame și am specificat titlul particular al coloanei cu funcția „.fillna()”. Între parantezele acestei metode am furnizat valoarea care va fi pusă în locurile nule. Numele DataFrame este „lipsește”, iar coloana pe care am ales-o aici este „M2”. Valoarea furnizată între acoladele „fillna()” este „0”. În cele din urmă, am apelat funcția „print()” pentru a vizualiza DataFrame-ul actualizat.

Aici, puteți vedea că coloana „M2” a DataFrame nu conține nicio valoare lipsă acum, deoarece valoarea NaN este completată cu 0.
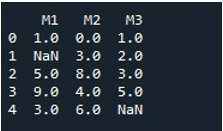
Pentru a completa valorile NaN pentru un întreg DataFrame cu aceeași metodă, am numit „fillna()”. Acest lucru este destul de simplu. Am furnizat numele DataFrame cu funcția „fillna()” și am atribuit valoarea funcției „0” între paranteze. În cele din urmă, funcția „print()” ne-a arătat DataFrame-ul umplut.

Acest lucru ne obține un DataFrame fără valori NaN, deoarece toate valorile sunt reumplute cu 0 acum.
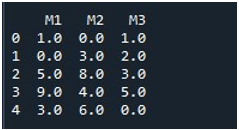
Exemplul 2: Completați valorile NaN utilizând metoda Pandas „Înlocuiți()”.
Această parte a articolului demonstrează o altă metodă de a completa valorile NaN într-un DataFrame. Vom folosi funcția „replace()” a lui Pandas pentru a completa valorile într-o singură coloană și într-un DataFrame complet.
Începem să scriem codul în instrumentul „Spyder”. Mai întâi, am importat bibliotecile necesare. Aici, am încărcat biblioteca Pandas pentru a permite programului Python să utilizeze metodele Pandas. A doua bibliotecă pe care am încărcat-o este NumPy și alias-o la „np”. NumPy gestionează datele lipsă cu metoda „replace()”.
Apoi, am generat un DataFrame având trei coloane – „șurub”, „cuie” și „găurire”. Valorile din fiecare coloană sunt date respectiv. Coloana „șurub” are valori „112”, „234”, „Niciuna” și „650”. Coloana „unghie” are „123”, „145”, „Niciuna” și „711”. În cele din urmă, coloana „drill” are valori „312”, „Niciuna”, „500” și „Niciuna”. DataFrame este stocat în obiectul „tool” DataFrame și afișat folosind metoda „print()”.
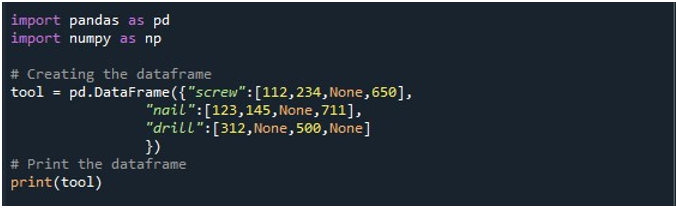
Un DataFrame cu patru valori NaN în înregistrare poate fi văzut în următoarea imagine de ieșire:
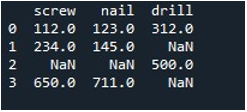
Acum, folosim metoda Pandas „replace()” pentru a completa valorile nule într-o singură coloană a DataFrame. Pentru sarcină, am invocat funcția „replace()”. Am furnizat numele DataFrame „instrument” și coloana „șurub” cu metoda „.replace()”. Între acolade, setăm valoarea „0” pentru intrările „np.nan” din DataFrame. Metoda „print()” este folosită pentru a afișa rezultatul.

DataFrame rezultat ne arată prima coloană cu intrări NaN înlocuite cu 0 în coloana „șurub”.
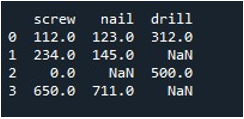
Acum, vom învăța să umplem valorile în întregul DataFrame. Am numit metoda „replace()” cu numele DataFrame și am furnizat valoarea pe care dorim să o înlocuim cu intrări np.nan. În cele din urmă, am tipărit DataFrame-ul actualizat cu funcția „print()”.

Acest lucru ne oferă DataFrame rezultat fără înregistrări lipsă.
Concluzie
Tratarea intrărilor lipsă dintr-un DataFrame este o cerință fundamentală și este necesară pentru a reduce complexitatea și a gestiona datele cu sfidătoare în procesul de analiză a datelor. Pandas ne oferă câteva opțiuni pentru a face față acestei probleme. Am adus două strategii utile în acest ghid. Punem în practică atât tehnicile cu ajutorul instrumentului „Spyder” pentru a executa exemplele de coduri pentru a face lucrurile puțin ușor de înțeles și mai ușor pentru tine. Dobândirea cunoștințelor despre aceste funcții vă va ascuți abilitățile Pandas.