„Pandas” este un limbaj excelent pentru efectuarea analizei datelor, datorită ecosistemului său mare de pachete python centrate pe date. Acest lucru facilitează analiza și importarea ambilor factori. Abaterea standard este o abatere „tipică” derivată din medie. Este folosit foarte mult, deoarece returnează unitățile de măsură inițiale ale cadrului de date. Pandas au folosit std() pentru calcularea abaterii standard. Abaterea standard poate fi calculată din valorile date care pot fi în cadrul de date sub forma unui rând sau coloană. Vom implementa toate modurile posibile în care este utilizată abaterea standard a panda. Pentru implementarea codului, vom folosi instrumentul „spyder”, așa cum este scris într-un mediu prietenos cu Python.”
Sintaxă
„df.std ( ) ”
Următoarea sintaxă este utilizată pentru calcularea abaterii standard în cadrul de date. „df” din cadrul de date este abrevierea „cadru de date”. Ce face abaterea standard? Măsoară cât de extinse sunt datele necesare. Cu cât valorile ridicate sunt mai extinse, cu atât ar trebui să apară abaterea standard mai mare.
Întoarcere
Abaterea standard panda returnează cadrul de date dacă nivelul este specificat pe baza cerinței.
Rețineți că funcția „std()” va ignora automat valorile „NaN” din „df” în timp ce calculează abaterea standard a panda. „NaN” poate fi explicat ca „nu este un număr”, ceea ce înseamnă că nu există nicio valoare atribuită unui anumit.
Următoarele sunt metodele care vor fi executate cu exemple de abatere standard a panda:
-
- Calculul abaterii standard panda într-o singură coloană.
- Calculul abaterii standard panda în mai multe coloane.
- Calculul abaterii standard Pandas pentru toate coloanele numerice.
- abaterea standard panda folosind axa = 1.
- abaterea standard panda folosind axa = 0.
Crearea cadrului de date pentru calculul abaterii standard în Pandas
Mai întâi, deschideți software-ul „spyder”. Acum importați biblioteca panda ca pd. Vom crea un cadru de date care constă dintr-un tablou de bord cu termeni ca „x”, „y” și „z” cu punctele lor ca „22”, „10”, „11”, „16”, „12”, „45”. ”, „36” și „40”. Avem valorile de asistență ca „8”, „9”, „13”, „7”, „22”, „24”, „4” și „6”, de asemenea, având valoarea recuperărilor ca „17”, „ 14”, „3”, 5”, „9”, „8”, „7” și „4”.
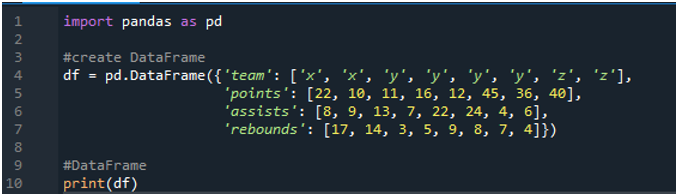
Afișajele arată cadrul de date creat conform valorilor atribuite în cod:

Exemplul # 01: Calculul deviației standard Pandas într-o singură coloană
În acest exemplu, vom calcula abaterea standard a unei singure coloane din cadrul de date Pandas. Cadrul de date are valorile echipei ca „u”, „v” și „b”, cu punctele lor ca „44”, „33”, „22”, „44”, „45”, „88”, „96 ” și „78”. Valorile asistăților sunt „7”,”8”, „9”, „10”, „11”, „14”, „18” și „17”, având, de asemenea, valorile recuperărilor ca „11”, „ 9”, „8”, „7”, „6”, „5”, „4” și „3”. Coloana „puncte” este selectată din cadrul de date pentru a calcula abaterea standard pe o singură coloană.
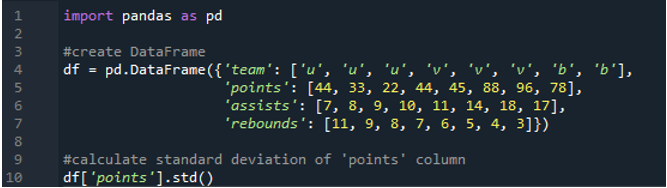
Ieșirea arată abaterea standard calculată a coloanei „puncte”:

Exemplul # 02: Calculul deviației standard Pandas în mai multe coloane
În acest exemplu, vom executa calculele deviației standard panda în mai multe coloane. În acest cadru de date, datele sunt din nou ale tabloului de bord sportiv având valorile echipei ca „n”, „w” și „t” cu scorul ca „33”, „22”, „66”, „55”, „44”, „88”, „99” și „77”. Asistă ca „9”, „7”, „8”, „11”, „16”, „14”, „12” și „13” și recuperări ca „5”, „8”, „1”, „ 2”, „3”, „4”, „6” și „7”. Aici vom calcula abaterea standard a celor două coloane „puncte” și „rebounds” folosind funcția std() aplicată cadrului de date.
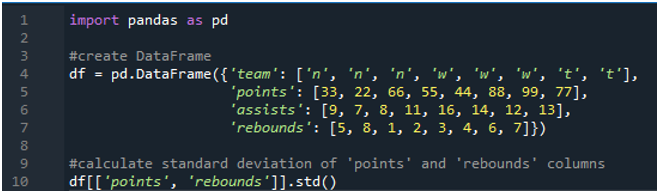
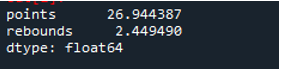
După cum vedem, rezultatul arată că abaterea standard a fost de 26,944387 în coloana de puncte și, respectiv, 2,449490 în coloana de rebound.
Exemplul # 03: Calculul deviației standard Pandas a tuturor coloanelor numerice
Acum am învățat cum să calculăm abaterea standard a rândurilor unice și multiple. Ce se întâmplă dacă nu dorim să specificăm toate numele coloanelor din cadrul de date și să calculăm întregul cadru de date? Acest lucru este posibil doar cu o simplă implementare a funcției a abaterii standard panda pentru calcularea întregului cadru de date în rezultate. Cadrul de date aici este format din „l”, „m” și „o” cu valorile de punctaj „33”, „36”, „79”, „78”, „58”, „55”, iar două echipe marchează la fel. adică „25”. Asistentele sunt „1”, „2”, „3”, „4”, „6”, „9”, „5” și „7”, iar recuperările lor ca „14”, „10”, „2” , „5”, „8”, „3”, „6” și „9”. Putem calcula toate abaterile standard ale coloanei de către panda din cadrul de date folosind funcția panda „std()”.
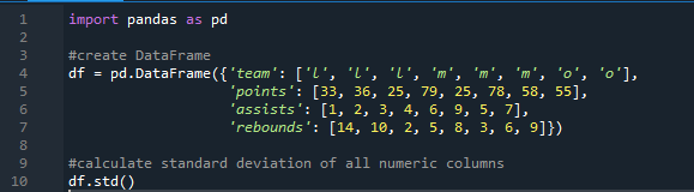
Afișajul are abaterea standard calculată a întregului „df” prezentat mai jos; mai putem observa că panda nu au calculat abaterea standard a primei coloane, care este „echipă”, deoarece nu este o coloană numerică.
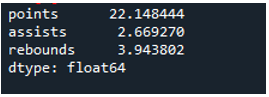
Exemplul # 04: Deviația standard a pandalor folosind axa = 0
În acest exemplu, cadrele de date au echipele sporturilor ca „g”, „h” și „k” cu date suplimentare. Aici, vom calcula abaterea standard utilizând axa ca „0”, un parametru utilizat în abaterea standard a panda. Acest argument calculează abaterea standard pe coloană a cadrului de date.
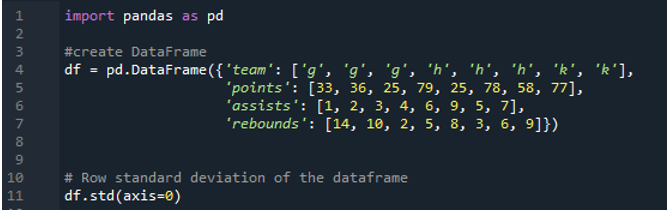
Următoarea ieșire afișează rezultatele în coloane ale abaterii standard calculate. Coloana de puncte are abaterea standard calculată ca „24,0313062”, coloana de asistență are abaterea standard calculată ca „2,669270”, iar abaterea standard calculată a coloanei de rebound este afișată ca „3,943802”.
Exemplul # 05: Deviația standard a pandalor folosind axa = 1
Aici vom folosi parametrul axei atribuit ca „1” pentru a calcula abaterea standard în panda. Ce diferență poate face axa „1”? Argumentul axei „1” calculează abaterea standard pe rând a valorilor numerice din cadrul de date. Cadrul de date are cele trei echipe ca „s”, „d” și „e”, cu adăugarea de coloane de date create ca puncte ale echipei, asistențe ale echipei și recuperări ale echipei. Toate direcțiile sunt atribuite cu valori diferite în cadrul de date. Acest parametru de axă este un astfel de schimbător de joc, deoarece, până la momentul respectiv, trebuie să lucrăm asupra datelor acolo unde vrem să fie într-o coloană plus punctul calculat al abaterii standard efectuate.
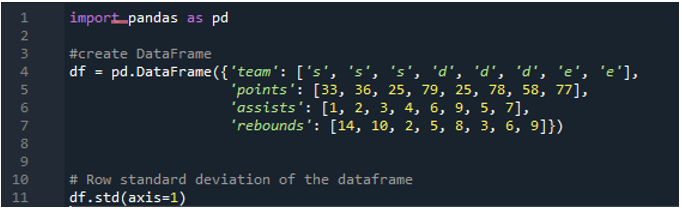
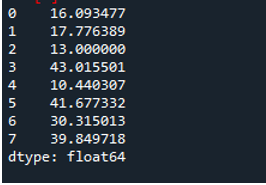
Următoarea ieșire afișează abaterea standard calculată într-un rând al cadrului de date:
Concluzie
Deviația standard a panda este o funcție foarte tehnică, care este o funcție foarte benefică, deoarece găsește abaterea standard a pactului de entuziasm al cadrelor de date panda. În acest editorial, am studiat metodele de calcul a abaterii standard la panda. Am efectuat calcule pe o singură coloană pentru abaterea standard și mai multe coloane și am calculat, de asemenea, abaterea standard a întregului cadru de date împreună. Toate strategiile funcționează bine atâta timp cât sunt utilizate în mod consecvent și cu rezultatele dorite.