Acest ghid va ilustra procesul de utilizare a memoriei de entitate în LangChain.
Cum se utilizează memoria entității în LangChain?
Entitatea este folosită pentru a păstra faptele cheie stocate în memorie pentru a le extrage atunci când este solicitat de om folosind interogări/prompt-uri. Pentru a afla procesul de utilizare a memoriei entității în LangChain, pur și simplu vizitați următorul ghid:
Pasul 1: Instalați module
Mai întâi, instalați modulul LangChain folosind comanda pip pentru a obține dependențele sale:
pip install langchain
După aceea, instalați modulul OpenAI pentru a obține bibliotecile sale pentru construirea de LLM-uri și modele de chat:
pip install openai
Configurați mediul OpenAI folosind cheia API care poate fi extrasă din contul OpenAI:
import tu
import getpass
tu . aproximativ [ „OPENAI_API_KEY” ] = getpass . getpass ( „Cheie API OpenAI:” )
Pasul 2: Utilizarea memoriei entității
Pentru a utiliza memoria entității, importați bibliotecile necesare pentru a construi LLM folosind metoda OpenAI():
din langchain. llms import OpenAIdin langchain. memorie import ConversationEntityMemory
llm = OpenAI ( temperatura = 0 )
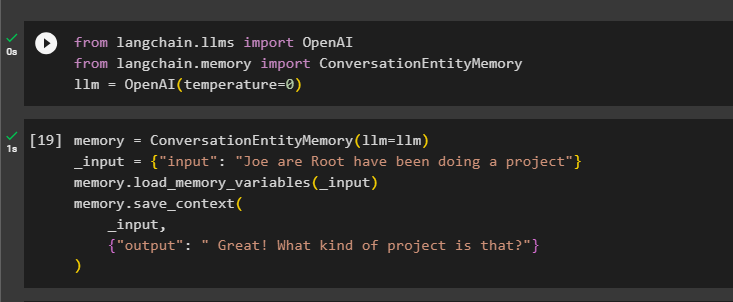
După aceea, definiți memorie variabilă folosind metoda ConversationEntityMemory() pentru a antrena modelul folosind variabilele de intrare și de ieșire:
memorie = ConversationEntityMemory ( llm = llm )_intrare = { 'intrare' : „Joe are Root a făcut un proiect” }
memorie. load_memory_variables ( _intrare )
memorie. salvare_context (
_intrare ,
{ 'ieșire' : 'Grozat! Ce fel de proiect este?' }
)
Acum, testați memoria folosind interogarea/promptul din intrare variabilă prin apelarea metodei load_memory_variables():
memorie. load_memory_variables ( { 'intrare' : „cine este Root” } ) 
Acum, dați mai multe informații, astfel încât modelul să poată adăuga câteva entități suplimentare în memorie:
memorie = ConversationEntityMemory ( llm = llm , return_messages = Adevărat )_intrare = { 'intrare' : „Joe are Root a făcut un proiect” }
memorie. load_memory_variables ( _intrare )
memorie. salvare_context (
_intrare ,
{ 'ieșire' : ' Grozav! Ce fel de proiect este acela' }
)
Executați următorul cod pentru a obține rezultatul folosind entitățile care sunt stocate în memorie. Este posibil prin intermediul intrare care conțin promptul:
memorie. load_memory_variables ( { 'intrare' : 'cine este Joe' } ) 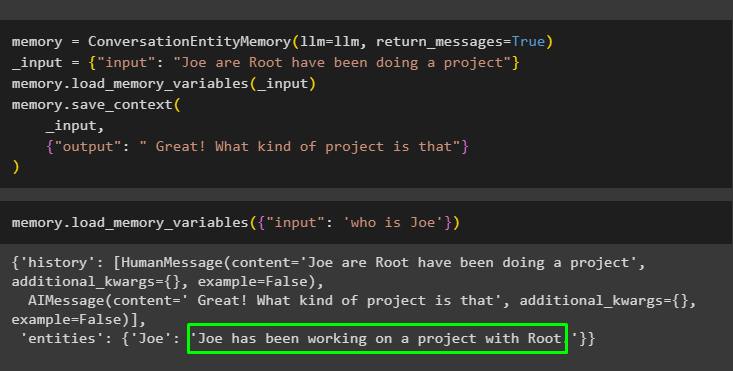
Pasul 3: Utilizarea memoriei entității într-un lanț
Pentru a utiliza memoria entității după construirea unui lanț, pur și simplu importați bibliotecile necesare folosind următorul bloc de cod:
din langchain. lanţuri import ConversationChaindin langchain. memorie import ConversationEntityMemory
din langchain. memorie . prompt import ENTITY_MEMORY_CONVERSATION_TEMPLATE
din pidantic import Model de bază
din tastare import Listă , Dict , Orice
Construiți modelul de conversație folosind metoda ConversationChain() folosind argumente precum llm:
conversaţie = ConversationChain (llm = llm ,
verboroasă = Adevărat ,
prompt = ENTITY_MEMORY_CONVERSATION_TEMPLATE ,
memorie = ConversationEntityMemory ( llm = llm )
)
Apelați metoda conversation.predict() cu intrarea inițializată cu promptul sau interogarea:
conversaţie. prezice ( intrare = „Joe are Root a făcut un proiect” ) 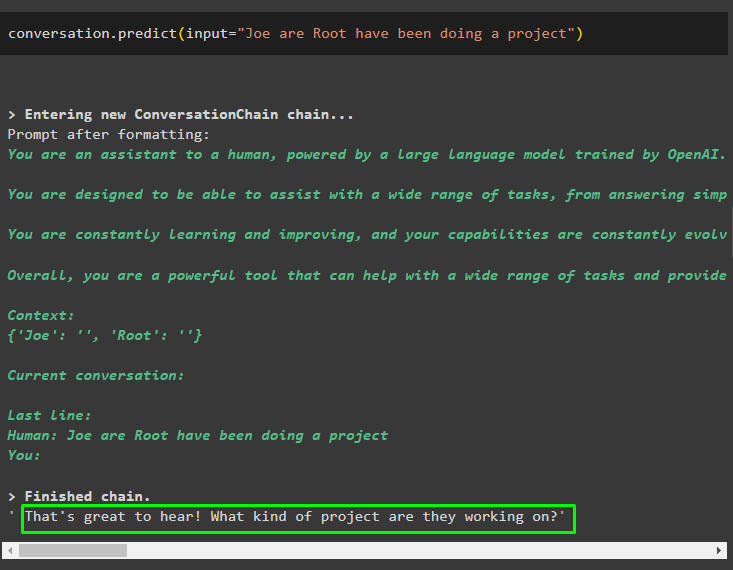
Acum, obțineți rezultatul separat pentru fiecare entitate care descrie informațiile despre aceasta:
conversaţie. memorie . entitate_magazin . magazin 
Utilizați rezultatul din model pentru a oferi intrarea, astfel încât modelul să poată stoca mai multe informații despre aceste entități:
conversaţie. prezice ( intrare = „Ei încearcă să adauge structuri de memorie mai complexe la Langchain” ) 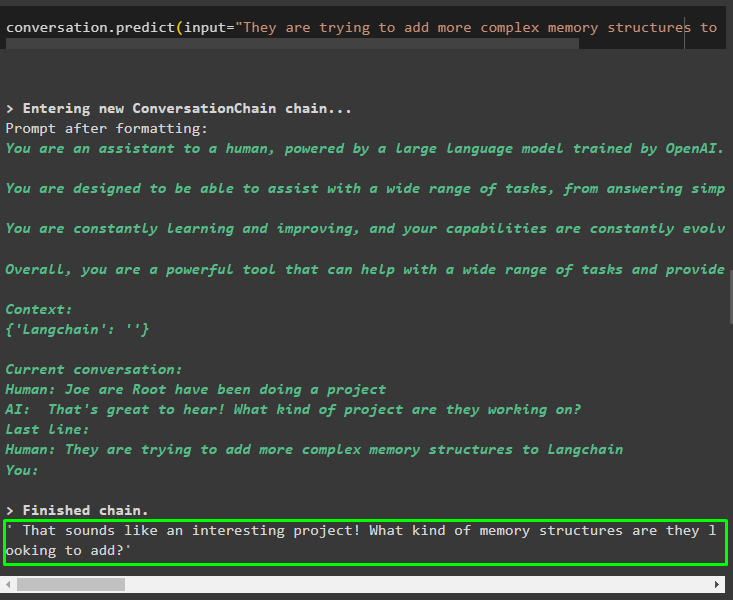
După ce ați dat informațiile care sunt stocate în memorie, pur și simplu puneți întrebarea pentru a extrage informațiile specifice despre entități:
conversaţie. prezice ( intrare = „Ce știi despre Joe și Root” ) 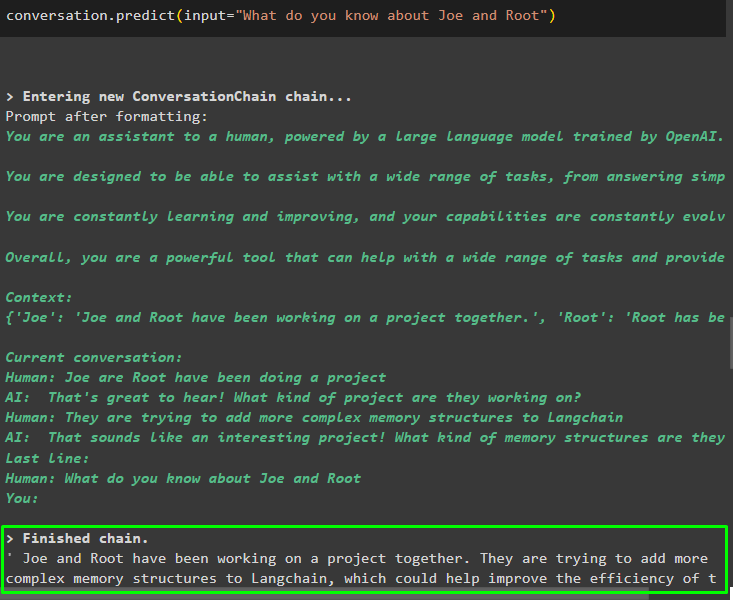
Pasul 4: Testarea depozitului de memorie
Utilizatorul poate inspecta direct depozitele de memorie pentru a obține informațiile stocate în ele folosind următorul cod:
din imprimare import imprimareimprimare ( conversaţie. memorie . entitate_magazin . magazin )
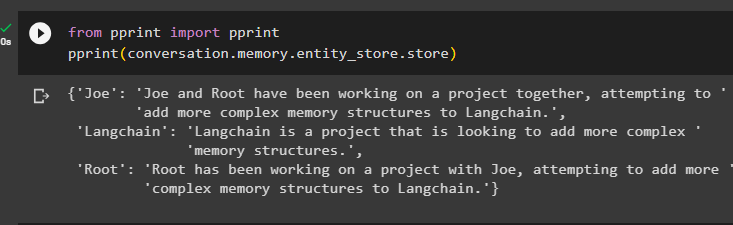
Furnizați mai multe informații pentru a fi stocate în memorie, deoarece mai multe informații oferă rezultate mai precise:
conversaţie. prezice ( intrare = „Root a fondat o afacere numită HJRS” ) 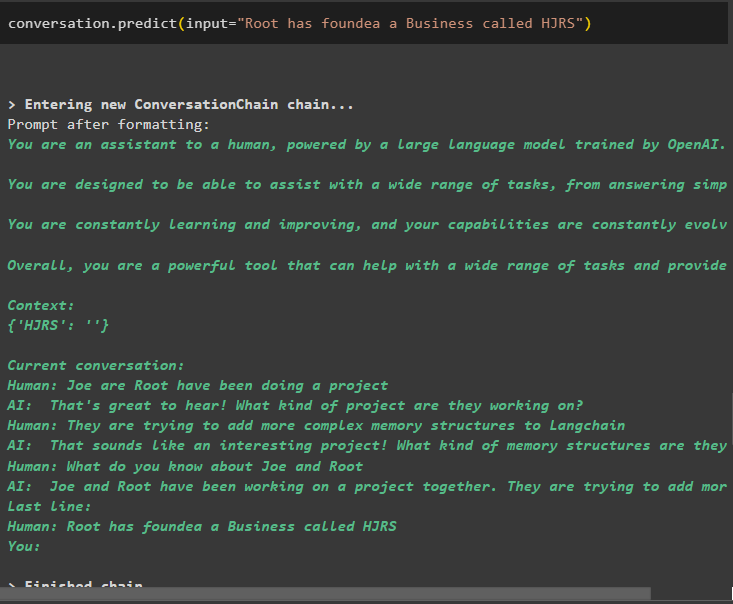
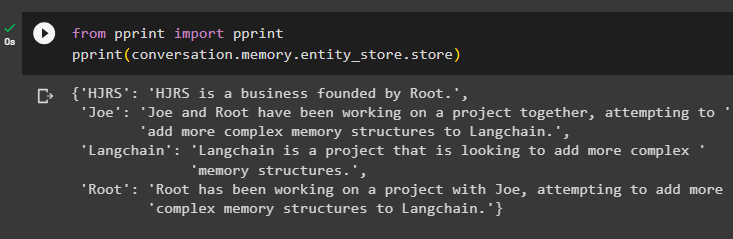
Extrageți informații din depozitul de memorie după ce adăugați mai multe informații despre entități:
din imprimare import imprimareimprimare ( conversaţie. memorie . entitate_magazin . magazin )
Memoria conține informații despre mai multe entități precum HJRS, Joe, LangChain și Root:
Acum extrageți informații despre o anumită entitate folosind interogarea sau promptul definit în variabila de intrare:
conversaţie. prezice ( intrare = „Ce știi despre Root” ) 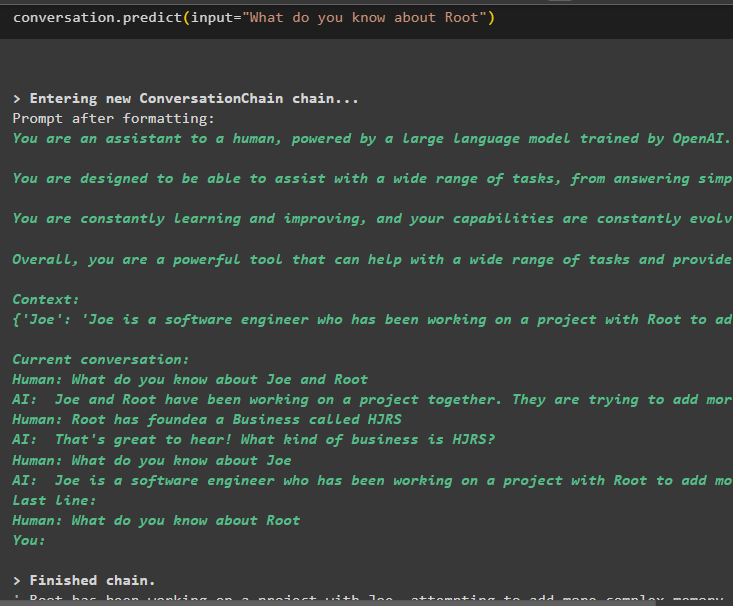
Este vorba despre utilizarea memoriei entității folosind cadrul LangChain.
Concluzie
Pentru a utiliza memoria entității în LangChain, instalați pur și simplu modulele necesare pentru a importa bibliotecile necesare pentru a construi modele după configurarea mediului OpenAI. După aceea, construiți modelul LLM și stocați entitățile în memorie furnizând informații despre entități. De asemenea, utilizatorul poate extrage informații folosind aceste entități și poate construi aceste amintiri în lanțuri cu informații agitate despre entități. Această postare a elaborat procesul de utilizare a memoriei entității în LangChain.