Schiță rapidă
Această postare conține următoarele secțiuni:
- Cum să utilizați un agent API asincron în LangChain
- Metoda 1: Utilizarea execuției în serie
- Metoda 2: Utilizarea execuției simultane
- Concluzie
Cum să utilizați un agent API Async în LangChain?
Modelele de chat efectuează mai multe sarcini simultan, cum ar fi înțelegerea structurii promptului, complexitățile sale, extragerea de informații și multe altele. Utilizarea agentului API Async în LangChain permite utilizatorului să construiască modele de chat eficiente care pot răspunde la mai multe întrebări simultan. Pentru a afla procesul de utilizare a agentului API Async în LangChain, pur și simplu urmați acest ghid:
Pasul 1: Instalarea cadrelor
Mai întâi de toate, instalați cadrul LangChain pentru a obține dependențele sale de la managerul de pachete Python:
pip install langchain
După aceea, instalați modulul OpenAI pentru a construi modelul de limbă precum llm și a seta mediul acestuia:
pip install openai
Pasul 2: Mediul OpenAI
Următorul pas după instalarea modulelor este stabilirea mediului folosind cheia API a OpenAI și Serper API pentru a căuta date de la Google:
import tu
import getpass
tu . aproximativ [ „OPENAI_API_KEY” ] = getpass . getpass ( „Cheie API OpenAI:” )
tu . aproximativ [ „SERPER_API_KEY” ] = getpass . getpass ( „Cheia API Serper:” )
Pasul 3: Importarea bibliotecilor
Acum că mediul este setat, pur și simplu importați bibliotecile necesare, cum ar fi asyncio și alte biblioteci folosind dependențele LangChain:
din langchain. agenţi import initialize_agent , load_toolsimport timp
import asincron
din langchain. agenţi import AgentType
din langchain. llms import OpenAI
din langchain. apeluri inverse . stdout import StdOutCallbackHandler
din langchain. apeluri inverse . trasoare import LangChainTracer
din aiohttp import ClientSession
Pasul 4: Configurați întrebări
Setați un set de date de întrebări care să conțină mai multe interogări legate de diferite domenii sau subiecte care pot fi căutate pe internet (Google):
întrebări = [„Cine este câștigătorul campionatului U.S. Open în 2021” ,
„Care este vârsta iubitului Oliviei Wilde” ,
„Cine este câștigătorul titlului mondial de Formula 1” ,
„Cine a câștigat finala feminină de la US Open în 2021” ,
„Cine este soțul lui Beyonce și ce vârstă are” ,
]
Metoda 1: Utilizarea execuției în serie
Odată ce toți pașii sunt finalizați, pur și simplu executați întrebările pentru a obține toate răspunsurile folosind execuția în serie. Înseamnă că o întrebare va fi executată/afișată la un moment dat și, de asemenea, va returna timpul complet necesar pentru a executa aceste întrebări:
llm = OpenAI ( temperatura = 0 )unelte = load_tools ( [ 'google-header' , 'llm-matematica' ] , llm = llm )
agent = initialize_agent (
unelte , llm , agent = AgentType. ZERO_SHOT_REACT_DESCRIPTION , verboroasă = Adevărat
)
s = timp . perf_counter ( )
#configurarea contorului de timp pentru a obține timpul folosit pentru întregul proces
pentru q în întrebări:
agent. alerga ( q )
scurs = timp . perf_counter ( ) - s
#printați timpul total folosit de agent pentru obținerea răspunsurilor
imprimare ( f „Serial executat în {elapsed:0.2f} secunde.” )
Ieșire
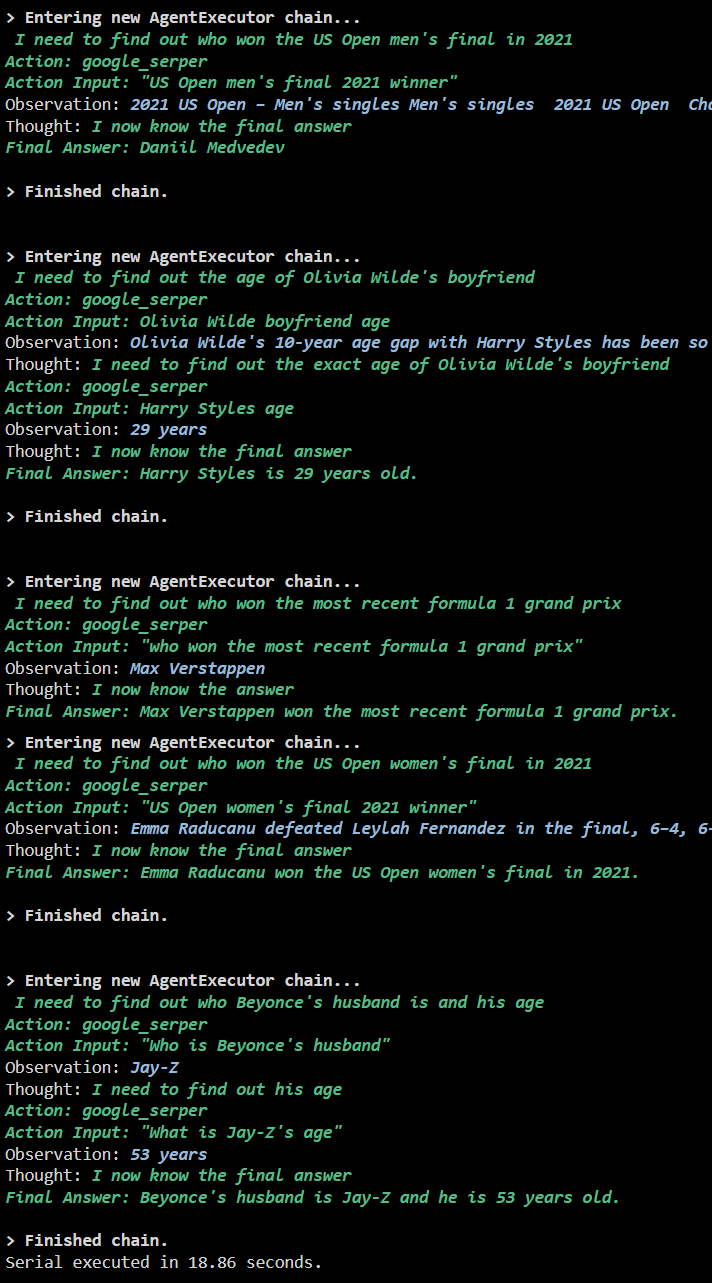
Următoarea captură de ecran arată că fiecare întrebare primește răspuns într-un lanț separat și odată ce primul lanț este terminat, al doilea lanț devine activ. Execuția în serie necesită mai mult timp pentru a obține toate răspunsurile individual:
Metoda 2: Utilizarea execuției simultane
Metoda de execuție simultană preia toate întrebările și primește răspunsurile lor simultan.
llm = OpenAI ( temperatura = 0 )unelte = load_tools ( [ 'google-header' , 'llm-matematica' ] , llm = llm )
#Configurarea agentului folosind instrumentele de mai sus pentru a obține răspunsuri simultan
agent = initialize_agent (
unelte , llm , agent = AgentType. ZERO_SHOT_REACT_DESCRIPTION , verboroasă = Adevărat
)
#configurarea contorului de timp pentru a obține timpul folosit pentru întregul proces
s = timp . perf_counter ( )
sarcini = [ agent. boala ( q ) pentru q în întrebări ]
asteapta asincronia. aduna ( *sarcini )
scurs = timp . perf_counter ( ) - s
#printați timpul total folosit de agent pentru obținerea răspunsurilor
imprimare ( f „Executat simultan în {elapsed:0.2f} secunde” )
Ieșire
Execuția simultană extrage toate datele în același timp și durează mult mai puțin decât execuția în serie:
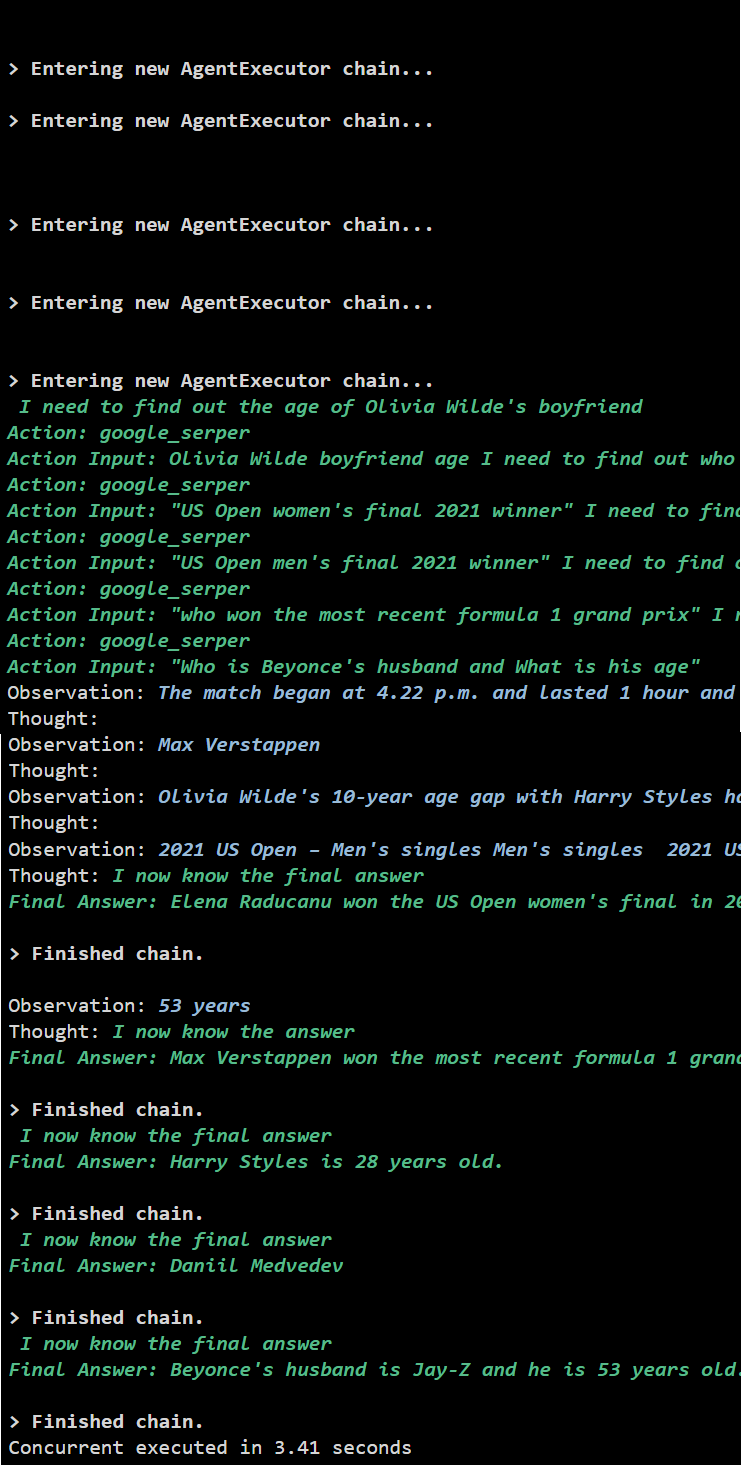
Acesta este totul despre utilizarea agentului API Async în LangChain.
Concluzie
Pentru a utiliza agentul API Async în LangChain, instalați pur și simplu modulele pentru a importa bibliotecile din dependențele lor pentru a obține biblioteca asincronă. După aceea, configurați mediile folosind cheile API OpenAI și Serper, conectându-vă la conturile respective. Configurați setul de întrebări legate de diferite subiecte și executați lanțurile în serie și concomitent pentru a obține timpul de execuție a acestora. Acest ghid a elaborat procesul de utilizare a agentului API Async în LangChain.